AWS OpenSearch로 블로그에 한국어 검색 기능 도입
1. 목표: 서버리스 검색 엔진 구축
Deep Dive! 블로그에 한국어 검색 기능을 도입하기로 결정했다. 목표는 다음과 같이 설정했다.
- 기술 스택: AWS OpenSearch Service를 핵심 검색 엔진으로 사용한다.
- 아키텍처: DynamoDB의 데이터 변경사항을 실시간으로 OpenSearch에 동기화하는 서버리스, 이벤트 기반 아키텍처를 구축한다.
- 핵심 요건: AWS 프리티어 범위를 준수하여 비용 발생을 최소화한다.
2. 아키텍처 설계
전체적인 데이터 흐름과 인프라 구조는 다음과 같이 설계했다.
- 데이터 원본: 모든 게시물 데이터는 DynamoDB 테이블(
postsTable)에 저장된다. - 데이터 변경 감지:
postsTable에 DynamoDB Streams를 활성화하여, 모든 데이터의 생성(INSERT), 수정(MODIFY), 삭제(REMOVE) 이벤트를 실시간으로 스트리밍한다. - 데이터 파이프라인: AWS Lambda (
indexing-handler) 가 DynamoDB Stream을 트리거로 구독한다. 스트림에서 변경된 데이터를 받아 OpenSearch가 이해할 수 있는 형태로 가공한다. - 검색 엔진: AWS OpenSearch Service 도메인을 생성하고,
posts라는 인덱스를 만들어 가공된 데이터를 저장(인덱싱)한다. - 검색 API: 사용자의 검색 요청을 처리할 API Gateway 엔드포인트(
/api/search)와, 이 요청을 받아 OpenSearch를 쿼리하는 AWS Lambda (search-handler) 를 구축한다. - 프론트엔드: Next.js 애플리케이션에서 검색 UI를 제공하고, 백엔드 검색 API를 호출하여 결과를 사용자에게 보여준다.
이 구조는 글쓰기 로직과 검색 인덱싱 로직을 분리(디커플링)하여 안정성을 높이고, 모든 구성요소가 서버리스로 동작하여 비용 효율성을 극대화하는 것을 목표로 했다. 보안을 위해 VPC는 도입하지 않고, IAM 역할 기반의 엄격한 접근 제어를 사용하기로 결정했다.
3. 인프라 구축 (AWS CDK)
모든 AWS 리소스는 재현성과 버전 관리를 위해 AWS CDK(Cloud Development Kit)를 사용하여 코드로 정의했다. 핵심 코드는 blog-stack.ts 파일에 작성했다.
3.1. OpenSearch 도메인 및 기본 인프라 정의
CDK를 사용하여 OpenSearch 도메인, 인덱싱 실패 시 이벤트를 저장할 SQS Dead-Letter Queue(DLQ), 그리고 각 Lambda 함수가 사용할 IAM 역할을 정의했다.
OpenSearch 도메인은 프리티어에 해당하는 t3.small.search 인스턴스 1대와 10GB EBS 볼륨으로 설정했다. 보안을 위해 Public Access로 설정하되, 리소스 기반 접근 정책을 통해 특정 IAM 역할(Lambda 함수들)만이 이 도메인에 접근할 수 있도록 엄격하게 제한했다.

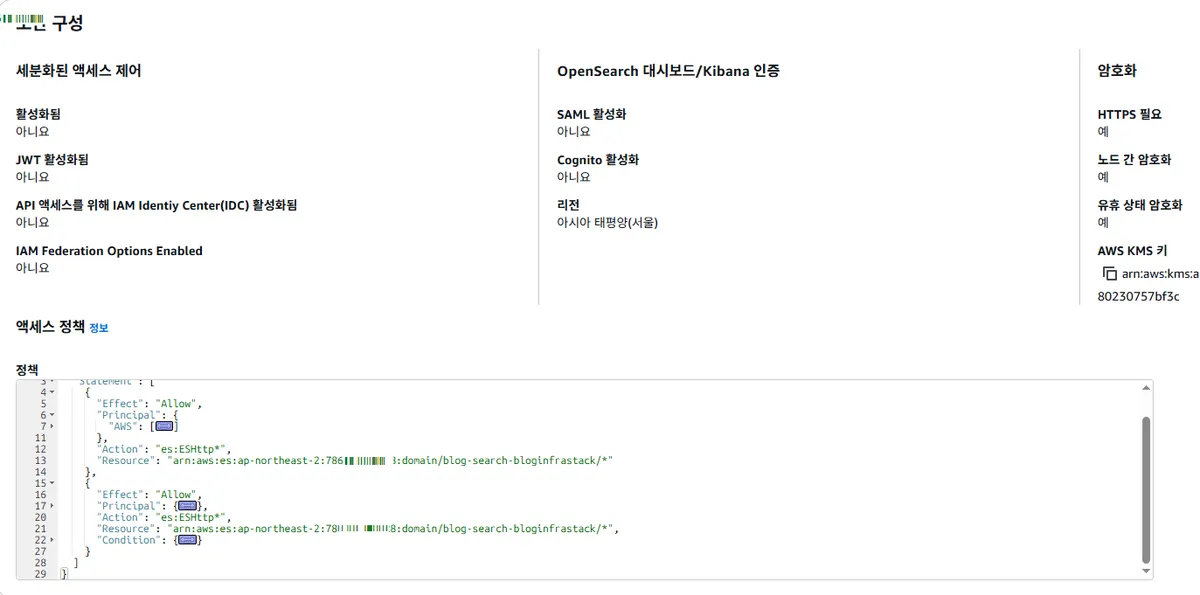
3.2. 한국어 분석기와의 싸움: Nori vs. Seunjeon
고품질의 한국어 검색을 위해서는 형태소 분석기가 필수적이었다. 처음에는 nori 분석기를 사용하려고 했으나, OpenSearch 버전과 AWS 리전(ap-northeast-2)의 조합에 따라 패키지 지원 여부가 달라지는 복잡한 문제에 직면했다.
수차례의 버전 업그레이드(2.11 -> 2.19 -> 3.1)와 배포 실패를 겪은 후, _cat/plugins API를 통해 현재 내가 사용하는 OpenSearch 3.1 버전에는 또 다른 한국어 분석기인 seunjeon이 기본 플러그인으로 내장되어 있음을 최종적으로 확인했다.
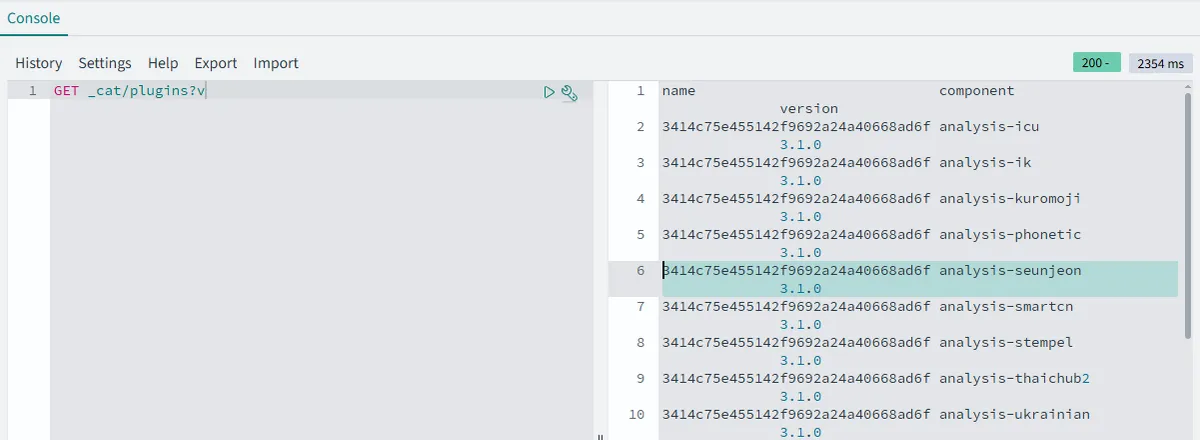
seunjeon은 별도의 설정 없이 즉시 사용 가능하며, 개인 블로그 규모에서는 nori와 체감할 만한 성능 차이가 없다고 판단하여 최종적으로 seunjeon을 채택했다.
3.3. 최종 인덱스 생성
seunjeon 분석기를 사용하도록 설정된 최종 posts 인덱스를 Dev Tools에서 PUT 명령어로 생성했다. title과 content 필드에 seunjeon_analyzer를 적용하여, 해당 필드들이 한국어 형태소 단위로 분석되어 저장되도록 설정했다.
4. 백엔드 구현: 데이터 파이프라인과 API
4.1. 인덱싱 Lambda 함수 (indexing-handler.ts)
DynamoDB Stream 이벤트를 받아 OpenSearch에 데이터를 동기화하는 Lambda 함수를 작성했다.
unmarshall유틸리티를 사용해 DynamoDB의 데이터를 표준 JSON으로 변환했다.- 이벤트의
eventName에 따라INSERT,MODIFY,REMOVE를 구분했다. 특히, 내 블로그는 게시물을 완전히 삭제하지 않고isDeleted: true플래그를 사용(soft delete)하므로,MODIFY이벤트에서 이 플래그가true가 되면 OpenSearch에서는 해당 문서를delete하도록 로직을 구현했다. - 여러 변경사항을 한번에 처리하기 위해 OpenSearch의
_bulkAPI를 사용했다. - 실패한 이벤트는 재시도 후 SQS DLQ로 보내 데이터 유실을 방지하도록 설정했다.
4.2. 검색 API Lambda 함수 (search-handler.ts)
사용자의 검색 요청을 처리하는 Lambda 함수를 작성했다.
- API Gateway로부터 검색어(
q)를 받는다. bool쿼리를 사용하여, 검색어와 일치하면서(must), 동시에 삭제되지 않았고(isDeleted: false), 공개된(visibility: public), 발행된(status: published) 게시물만을 찾아 반환하도록 보안 필터링을 추가했다.simple_query_string쿼리를 사용하여title과content필드를 검색하도록 했다.
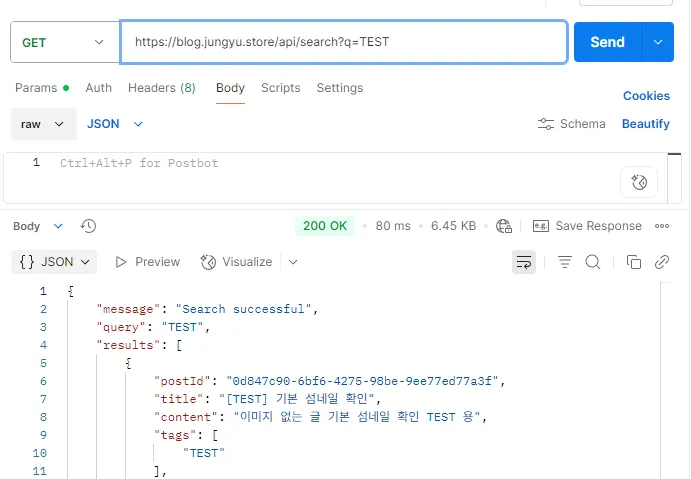
5. 프론트엔드 연동: 검색 경험의 완성
백엔드 API가 완벽하게 준비되었으므로, 이제 사용자가 실제로 검색 기능을 사용할 수 있도록 프론트엔드 UI를 구현할 차례였다.
5.1. 검색창 컴포넌트 (Search.tsx)
헤더에 위치하여 어느 페이지에서든 접근할 수 있는 검색창 컴포넌트를 만들었다.
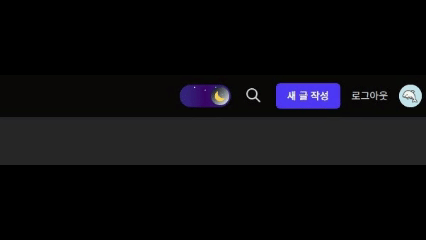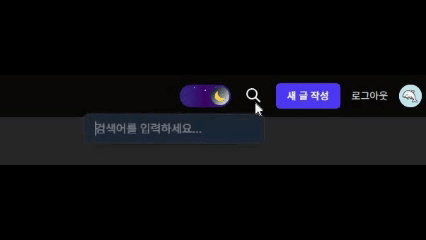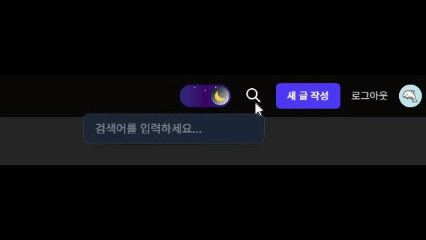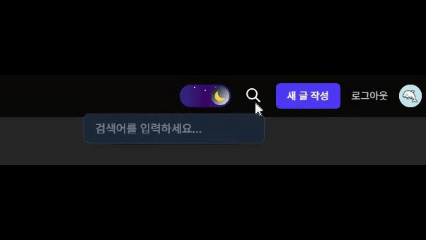
- 기본적으로는 돋보기 아이콘만 표시된다.
- 아이콘을 클릭하면
framer-motion을 사용한 부드러운 애니메이션과 함께 검색 입력창이 나타난다. - 사용자가 검색어를 입력하고 엔터를 누르면,
next/navigation의useRouter를 사용하여/search?q={검색어}경로로 이동시킨다.
5.2. 검색 결과 페이지 (/search/page.tsx)
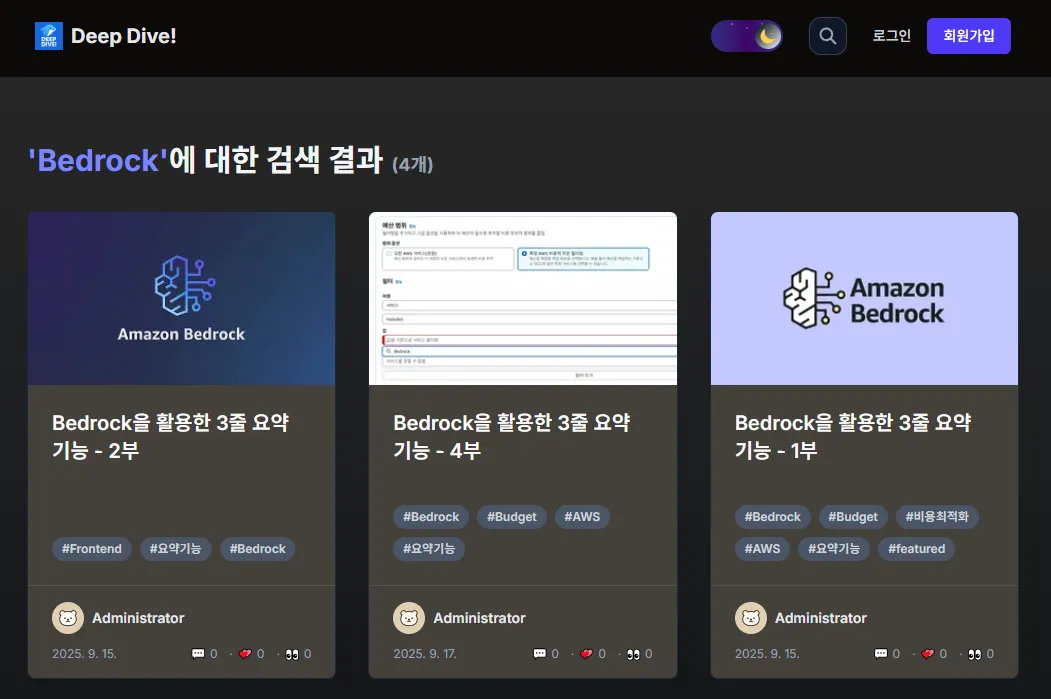
검색 결과를 보여주는 전용 페이지를 생성했다. 이 과정에서 Next.js App Router의 중요한 개념을 적용해야 했다.
useSearchParams와 Suspense: URL의 쿼리 파라미터를 읽는useSearchParams훅은 클라이언트 사이드에서만 동작한다. App Router의 페이지는 기본적으로 서버 컴포넌트이므로, 이 훅을 직접 사용하면 빌드 시점에 에러가 발생했다. 이 문제를 해결하기 위해,useSearchParams를 사용하는 로직을 별도의 클라이언트 컴포넌트(SearchResults.tsx)로 분리하고, 메인 페이지(page.tsx)에서 이 컴포넌트를<Suspense>로 감싸주었다.- 데이터 페칭:
SWR을 사용하여/api/search엔드포인트를 호출했다.SWR이 제공하는isLoading,error,data상태를 활용하여 로딩 중일 때, 에러가 발생했을 때, 그리고 검색 결과가 없을 때 각각 다른 UI를 보여주도록 구현했다. - 컴포넌트 재사용: 검색 결과 목록은 이미 만들어 둔
PostCard와PostCardSkeleton컴포넌트를 그대로 재사용하여, 코드의 중복을 줄이고 디자인의 일관성을 유지했다.
6. 기존 데이터 마이그레이션
모든 기능을 구현하고 배포한 뒤, 한 가지 중요한 사실을 깨달았다. 검색 기능은 새로 작성하거나 수정한 글에 대해서만 동작한다는 것이었다. DynamoDB Streams는 '변경'이 발생한 데이터만 감지하기 때문에, 검색 기능이 구축되기 이전에 존재했던 수십 개의 기존 게시물들은 OpenSearch에 전혀 인덱싱되지 않은 상태였다.
이 문제를 해결하기 위해, 일회성 데이터 마이그레이션 스크립트(migrate-to-opensearch.ts)를 작성했다.
- 스크립트 로직:
- AWS SDK를 사용하여 DynamoDB의
postsTable을 전체 스캔(Scan)하여 모든 게시물 데이터를 가져온다. - 삭제된(
isDeleted: true) 게시물은 제외한다. - 가져온 데이터를 OpenSearch의
_bulkAPI 형식에 맞게 가공한다. - 가공된 데이터를 OpenSearch에 한 번에 전송하여 모든 기존 게시물을 인덱싱한다.
- AWS SDK를 사용하여 DynamoDB의
- 실행: 이 Node.js 스크립트를 로컬 환경에서 실행하여, 배포된
BlogPosts-BlogInfraStack테이블의 모든 데이터를 OpenSearch에 성공적으로 마이그레이션했다.
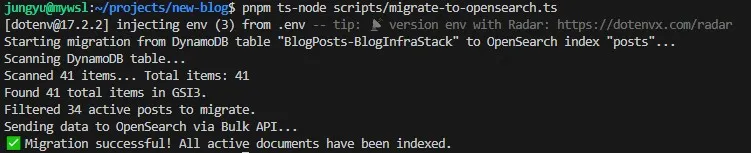 이 작업을 통해, 마침내 블로그의 과거와 현재 모든 게시물이 검색 가능하게 되었다.
이 작업을 통해, 마침내 블로그의 과거와 현재 모든 게시물이 검색 가능하게 되었다.
7. 최종 결과 및 회고
길고 험난한 과정을 거쳐, "Deep Dive!" 블로그는 마침내 seunjeon 한국어 형태소 분석기를 탑재한 고성능 서버리스 검색 엔진을 갖추게 되었다.
이번 프로젝트를 통해 배운 점은 다음과 같다.
- 문서의 중요성: AWS 서비스의 버전과 리전에 따라 기능 지원 여부가 크게 달라질 수 있다는 점을 깨달았다. 항상 최신 공식 문서를 교차 확인하는 습관이 얼마나 중요한지 체감했다.
- 문제 해결 과정: "안된다"는 현상 앞에서, 개발자 도구, CloudWatch Logs, AWS CLI 등 사용 가능한 모든 도구를 활용하여 문제의 근본 원인을 체계적으로 추적하고 가설을 검증하는 과정의 중요성을 다시 한번 느꼈다.
- 서버리스 아키텍처: DynamoDB Streams와 Lambda를 이용한 이벤트 기반 아키텍처가 얼마나 강력하고 유연한지 직접 경험할 수 있었다.
이제 사용자들은 블로그의 어떤 글이든 쉽게 검색 기능을 통하여 찾아볼 수 있게 되었다.
