#4. Next.js 블로그 고도화: 메인 페이지 재구성
1. 도입
'Deep Dive!'의 초기 버전 메인 페이지는 최신 게시물을 시간순으로 나열하는 단순한 목록 형태였다. 기능적으로 문제가 없고 심플한 게시물 목록을 볼 수 있었다. 하지만 메인 페이지에 처음 접속했을 때, 조금 더 시각적으로 흥미를 이끌 요소가 필요했다. 단순한 최신순 전체 게시물 목록에서 잘 작성된 추천 콘텐츠를 노출하는 동적인 공간으로 재구성하는 고도화 작업을 진행했다.
최종 목표는 다음과 같은 구조를 가진 메인 페이지를 구현하는 것이었다.
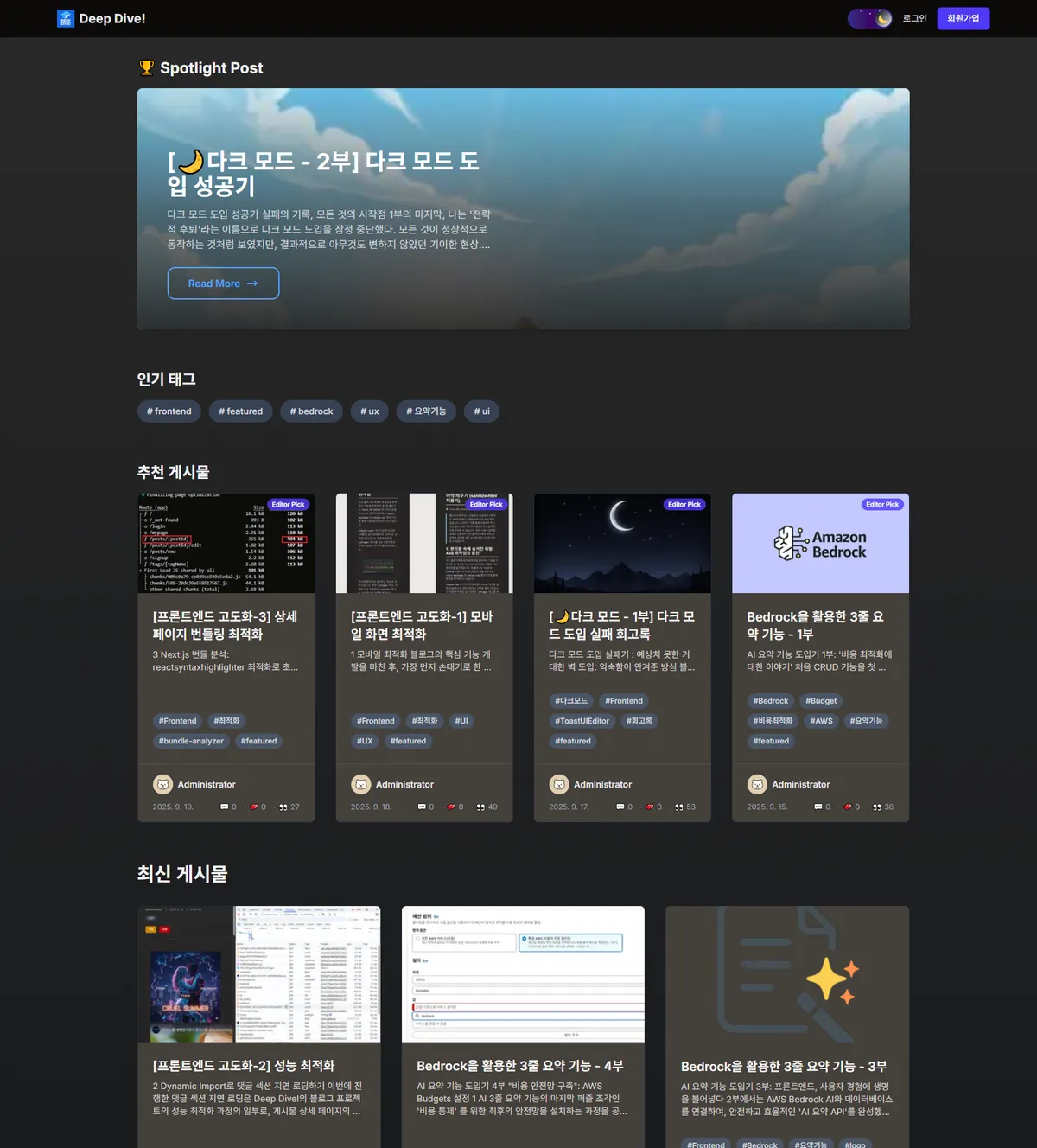
- 대표 게시물 (Spotlight Post): 블로그의 핵심 정체성을 보여주는 단 하나의 게시물
- 주요 토픽 (인기 태그): 주요 카테고리를 탐색할 수 있는 태그 목록
- 추천 게시물 (Editor Pick): 관리자가 직접 선별한 여러 개의 추천 글
- 전체 게시물 (최신순): 기존의 시간순 전체 게시물 목록
2. 아키텍처 설계
고도화의 핵심 목표는 '관리자가 추천 콘텐츠를 유연하게 제어'하는 것이었다. 이를 위해 초기 아이디어였던 특정 태그('featured')를 사용하는 방식의 한계를 검토했다. 여러 글에 태그를 잘못 다는 실수나, 대표 게시물을 하나만 지정하기 어려운 문제, 그리고 향후 다른 전역 설정 추가의 어려움 등이 예상되었다.
이러한 한계를 극복하고자, 더 견고하고 확장 가능한 데이터 모델을 도입했다.
'SITE_CONFIG' 아이템 도입
DynamoDB에 PK: 'SITE_CONFIG' 라는 고유한 아이템을 생성하여, 블로그 전체의 설정을 한 곳에서 관리하는 '단일 진실 공급원(Single Source of Truth)'으로 삼았다.
// DynamoDB의 SITE_CONFIG 아이템 구조 { "PK": "SITE_CONFIG", "SK": "METADATA", "heroPostId": "a1b2c3d4-..." // 대표 게시물의 ID }
이 구조는 대표 게시물을 명확하게 지정하여 운영상의 실수를 방지한다. 또한 향후 공지사항이나 이벤트 배너 같은 새로운 전역 설정이 필요할 때 SITE_CONFIG 아이템에 속성을 추가하는 것만으로 유연하게 확장할 수 있는 기반이 된다.
3. 백엔드 API 구현
새로운 아키텍처를 지원하기 위해 백엔드(Hono 기반)에 두 개의 핵심 API를 구현했다.
3.1. 추천 데이터 조회 API: GET /api/posts/featured
메인 페이지 렌더링에 필요한 모든 추천 데이터를 한 번에 반환하는 API이다.
- 동작 로직:
SITE_CONFIG아이템을 조회하여heroPostId를 가져온다.heroPostId로 대표 게시물(Hero Post) 데이터를 조회한다.- 'featured' 태그가 붙은 게시물 목록을 조회하여, Hero 게시물을 제외한 나머지를 추천 게시물(Editor's Picks)로 구성한다.
- 최종적으로
{ heroPost: Post, editorPicks: Post[] }형태의 객체를 반환한다.
3.2. 대표 게시물 수정 API: PUT /api/config/hero (관리자 전용)
운영 편의성을 위해, 관리자가 API를 통해 대표 게시물을 직접 변경할 수 있는 엔드포인트를 추가했다.
- 동작 로직:
adminOnlyMiddleware를 통해 관리자만 API를 호출할 수 있도록 보호한다.- 요청 본문으로 받은
postId를SITE_CONFIG아이템의heroPostId값으로 업데이트한다.
이 API를 통해 데이터베이스에 직접 접근하거나 코드를 재배포할 필요 없이, 사이트의 핵심 콘텐츠를 유연하게 변경할 수 있는 시스템을 구축했다.
4. 인프라 코드(CDK)를 통한 초기 데이터 관리
모든 AWS 리소스를 코드로 관리(IaC)하는 원칙에 따라, SITE_CONFIG 아이템 또한 AWS CDK를 통해 관리하도록 설정했다.
aws-cdk-lib/custom-resources의 AwsCustomResource를 사용하여, CDK 스택 배포 시 SITE_CONFIG 아이템이 존재하지 않으면 지정된 초기값으로 아이템을 생성하는 로직을 blog-stack.ts에 추가했다. 이는 배포 환경의 안정성과 데이터 일관성을 보장하는 '안전망' 역할을 한다. 실제 운영 중 heroPostId 값의 변경은 위에서 구현한 관리자용 API를 통해 이루어진다.
// apps/infra/lib/blog-stack.ts의 일부 new cr.AwsCustomResource(this, 'SiteConfigSeeder', { onCreate: { service: 'DynamoDB', action: 'putItem', parameters: { TableName: postsTable.tableName, Item: { PK: { S: 'SITE_CONFIG' }, SK: { S: 'METADATA' }, heroPostId: { S: 'INITIAL_HERO_POST_ID' } } }, physicalResourceId: cr.PhysicalResourceId.of('SiteConfigSeeder-Initial-Data'), }, policy: cr.AwsCustomResourcePolicy.fromSdkCalls({ resources: [postsTable.tableArn] }), });
5. 프론트엔드 구현
백엔드 API 준비가 완료된 후, 프론트엔드에서 이 데이터를 활용하여 목표한 UI를 구성하는 작업을 시작했다. 이 과정은 API 클라이언트 수정, 신규 UI 컴포넌트 개발, 그리고 최종 페이지 조립의 세 단계로 진행되었다.
5.1. API 클라이언트 확장
먼저, 백엔드의 새로운 응답 구조({ heroPost, editorPicks })에 맞춰 프론트엔드의 API 클라이언트(utils/api.ts)를 수정했다. fetchFeaturedPosts 함수의 반환 값 타입을 명확히 정의하여, 애플리케이션 전체에서 데이터의 형태를 예측하고 타입 안정성을 보장하도록 했다.
// apps/frontend/src/utils/api.ts의 일부 // 추천 데이터 API의 새로운 응답 타입을 정의 export interface FeaturedData { heroPost: Post | null; editorPicks: Post[]; } export const api = { // ... // fetchFeaturedPosts 함수의 반환 값 타입을 새로운 FeaturedData로 변경 fetchFeaturedPosts: (): Promise<FeaturedData> => { return fetchWrapper('/posts/featured', { method: 'GET' }); }, // ... };
5.2. UI 컴포넌트 설계 및 분리
메인 페이지의 각 섹션은 독립적인 역할을 수행하므로, 재사용성과 유지보수성을 높이기 위해 각 UI를 별도의 컴포넌트로 분리하여 개발했다.
FeaturedPostCard.tsx(대표 게시물 카드): Hero Section을 위한 전용 컴포넌트이다. 일반 카드와 달리, 이미지를 전체 배경으로 사용하고 그 위에 어두운 그라데이션 오버레이를 씌워 텍스트 가독성을 확보했다. 제목, 요약, 'Read More' 버튼을absolute포지션으로 배치하여 목표했던 디자인을 구현했다.
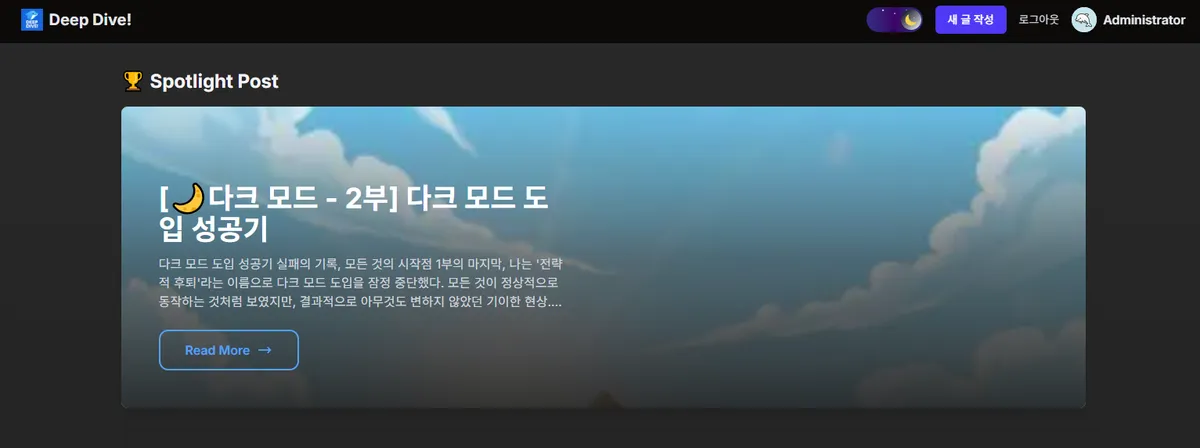
PostCard.tsx(기존 카드 수정): "Editor's Picks" 목록을 시각적으로 구분하기 위해, 기존PostCard컴포넌트에isEditorPick?: boolean이라는 선택적 prop을 추가했다. 이 prop이true로 전달될 경우에만, 이미지 우측 상단에 "Editor Pick" 배지가 조건부로 렌더링되도록 수정했다. 이를 통해 컴포넌트의 재 사용성을 유지하면서 새로운 요구 사항을 만족시켰다.
TagFilter.tsx(태그 탐색 컴포넌트): "Explore Topics" 섹션을 위해, 인기 태그 목록을 보여주는TagFilter컴포넌트를 새로 생성했다. 이 컴포넌트는 페이지의 다른 데이터와 독립적으로 동작하므로, 클라이언트 사이드에서useSWR훅을 사용하여GET /api/tags/popularAPI를 호출하고 데이터를 렌더링하도록 구현했다.
5.3. 페이지 조립 및 데이터 흐름
마지막으로, 메인 페이지 컴포넌트(app/page.tsx)에서 위에서 만든 모든 조각들을 최종적으로 조립했다.
-
병렬 데이터 페칭: 페이지 로딩 속도를 최적화하기 위해,
Promise.all을 사용하여 '추천 데이터'(fetchFeaturedPosts)와 '최신 글 목록'(fetchPosts)을 서버에서 병렬로 동시에 요청했다. -
데이터 처리 및 전달: API로부터 받은
featuredData는heroPost와editorPicks로 분리했다. 이 데이터와initialPostsData를 각각<FeaturedSection>과<PostList>컴포넌트에 prop으로 전달했다. 또한, 추천 영역에 표시된 게시물이 최신 글 목록에 중복으로 나타나지 않도록, 추천된 게시물 ID 배열(featuredPostIds)을PostList에 전달하여 필터링하도록 했다. -
로딩 상태 처리 (
Suspense): 서버 컴포넌트 환경의 장점을 활용하여,Suspense로 데이터 페칭이 완료되지 않은 컴포넌트를 감쌌다.fallback으로는 각 섹션에 맞는 스켈레톤 UI를 조합한<HomePageSkeleton />을 지정하여, 사용자가 데이터를 기다리는 동안 페이지의 전체적인 윤곽을 미리 볼 수 있도록 사용자 경험을 개선했다.
// apps/frontend/src/app/page.tsx의 최종 구조 export default async function HomePage() { try { const [featuredData, initialPostsData] = await Promise.all([ api.fetchFeaturedPosts(), api.fetchPosts(POSTS_PER_PAGE, null) ]); const { heroPost, editorPicks } = featuredData; const featuredPostIds = [ ...(heroPost ? [heroPost.postId] : []), ...editorPicks.map(p => p.postId) ]; return ( <div> <Suspense fallback={<HomePageSkeleton />}> <FeaturedSection heroPost={heroPost} editorPicks={editorPicks} /> </Suspense> <h1 className="text-3xl font-bold mb-8 dark:text-gray-100">최신 게시물</h1> <PostList fallbackData={initialPostsData} excludeIds={featuredPostIds} /> </div> ); } catch (err) { // ... } }
6. 최종 결과 및 향후 과제
이 과정을 통해 Deep Dive! 블로그의 메인 페이지는 정적인 목록에서, 관리자가 직접 콘텐츠를 큐레이션하고 블로그의 첫 인상을 전략적으로 구성할 수 있는 동적인 공간으로 성공적으로 재탄생했다.
백엔드에서는 확장성을 고려한 데이터 모델과 유연한 관리 API를 구축했으며, 프론트엔드에서는 서버 컴포넌트의 장점을 활용하여 효율적인 데이터 페칭과 점진적인 UI 렌더링을 구현했다.
프론트엔드 고도화는 여기서 멈추지 않는다. 다음 단계로는 이 풍부해진 메인 페이지를 바탕으로, 긴 글의 가독성을 높이는 '게시물 목차(Table of Contents)' 기능과 사용자가 원하는 정보를 쉽게 찾을 수 있는 '검색 기능'을 추가하여 블로그의 사용성을 지속적으로 개선해 나갈 예정이다.
