
AI 요약 기능 도입기 1부: '비용 최적화에 대한 이야기'
처음 CRUD 기능을 첫 목표로 시작한 Deep Dive! 블로그에 많은 기능들이 추가되었다. 태그 분류, Markdown 에디터 도입, 이미지 및 외부 동영상 업로드 기능, 댓글과 좋아요 등의 소셜 기능을 추가하고 나니 제법 블로그의 느낌이 났다. 이제는 대형 플랫폼에서 제공하는 블로그 기능과는 차별화된 기능을 추가하고 싶었다. 많은 아이디어를 고민하던 찰나에 좋은 아이디어가 떠올랐다. 바로 Bedrock을 이용한 '게시물 3줄 요약' 기능이다. 독자가 긴 글을 읽기 전에, AI가 생성한 요약을 통해 글의 핵심을 빠르게 파악할 수 있다면 더 좋은 경험을 제공할 수 있을 거라 생각했다. 하지만 아이디어의 설렘도 잠시, 가장 현실적인 질문이 머릿속을 스쳤다.
"그래서, Bedrock을 사용하면 비용은 얼마나 나올까?"
AI 모델을 호출하는 것은 공짜가 아니다. 만약 수많은 방문자가 이 기능을 계속 사용한다면, 내 예산을 훌쩍 뛰어넘는 요금이 청구될 수도 있는 일이었다. 단순히 기능을 구현하는 것을 넘어, 이 기능을 '지속 가능하게' 만드는 방법을 찾아야만 했다. 이것은 AI 요약 기능 도입의 첫 번째 관문인, '비용' 문제를 해결하기 위한 나의 탐색 기록이다.
첫 번째 탐색: 비용의 기준, '글자 수'가 아닌 '토큰'
처음에는 막연히 글의 길이를 기준으로 비용을 예상했다. 내 블로그의 최근 포스팅한 게시물 하나를 가져와 글자 수를 확인해 보았다.

- 이미지:
글자수/바이트 측정 스크린샷 - 캡션 (예시): 공백 포함 약 8,900자, 꽤 긴 분량의 텍스트였다.
하지만 생성형 AI의 비용은 '글자 수'가 아닌 '토큰(Token)' 이라는 단위로 책정된다. 토큰은 AI가 언어를 이해하고 처리하는 기본적인 단위로, 보통 단어나 구두점 등으로 나뉜다. 특히 한글과 같은 언어는 영어에 비해 같은 글자 수라도 더 많은 토큰을 사용하는 경향이 있다.
정확한 비용을 예측하려면, 내 게시물이 실제로 몇 개의 토큰으로 변환되는지 측정하는 과정이 필요했다.
두 번째 탐색: 내 게시물의 실제 '토큰' 측정하기
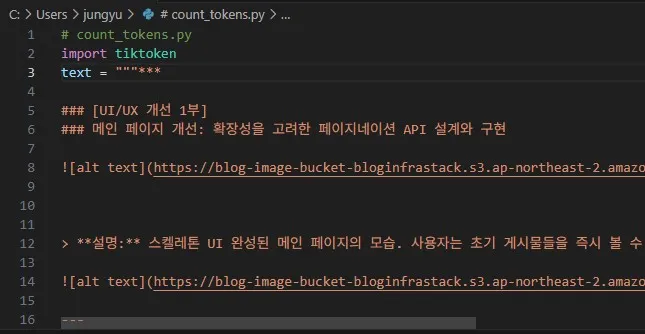
정확한 토큰 수를 측정하기 위해, OpenAI나 Anthropic(Claude 모델 개발사)과 호환되는 tiktoken이라는 Python 라이브러리를 사용하기로 했다. 간단한 스크립트를 작성하여, 아까 그 게시물의 실제 토큰 수를 측정해 보았다.
# count_tokens.py import tiktoken # text 변수에 실제 게시물 본문을 붙여넣었다. text = """ ### [UI/UX 개선 1부] ### 메인 페이지 개선: 확장성을 고려한 페이지네이션 API 설계와 구현  ... > **설명:** 스켈레톤 UI 완성된 메인 페이지의 모습. 사용자는 초기 게시물들을 즉시 볼 수 있으며, ... (생략) """ enc = tiktoken.get_encoding("cl100k_base") tokens = enc.encode(text) print("토큰 수:", len(tokens))
결과는 예상보다 흥미로웠다.
- 이미지:
count_tokens.py 실행 결과 스크린샷 - 캡션 (예시): 8,900자 텍스트가 5271 토큰으로 측정되었다.
약 8,900자의 한글 텍스트가 5271개의 토큰으로 변환되었다. 이제 이 실측 데이터를 기반으로, 실제 비용을 계산해 볼 수 있게 되었다.
세 번째 탐색: 모델 선택과 비용 계산
나는 앞서 AWS의 생성형 AI 서비스인 Amazon Bedrock을 사용하기로 결정했다. Bedrock을 통해 다양한 AI 모델을 쉽게 사용할 수 있는데, 그중 Anthropic의 Claude 3 모델 군이 눈에 들어왔다.
- Claude 3 Sonnet: 고품질, 고성능 모델
- Claude 3 Haiku: 속도와 비용 효율성에 중점을 둔 모델
내 블로그 게시물의 평균 입력 토큰을 약 5,300개, AI가 생성할 3줄 요약의 출력 토큰을 약 100개로 가정하고, 아주 넉넉히 한 달에 500번의 요약 요청이 발생한다고 시뮬레이션했다.
- Sonnet 모델 사용 시: 월 약 $8.66
- Haiku 모델 사용 시: 월 약 $0.72
결과는 명확했다. 게시물 요약과 같은 작업에는 Claude 3 Haiku 모델의 성능만으로도 충분하며, 비용은 거의 무시할 수 있는 수준이었다. 이로써 '어떤 AI 모델을 사용할 것인가'와 '한 번 호출에 얼마가 드는가'에 대한 답을 얻었다.
마지막 관문: 사용량 폭증에 대한 아키텍처적 해결책
하지만 아직 진짜 문제가 남아있었다. "만약 한 명의 사용자가 100개의 게시물 요약을 요청하거나, 100명의 사용자가 같은 게시물의 요약을 요청하면 어떻게 될까?"
단순히 API를 호출하는 방식으로는, 사용자의 행동에 따라 비용이 예측 불가능하게 증가할 수 있었다. 이 문제를 해결하기 위해서는 기능의 구조 자체를 다시 생각해야 했다.
그래서 나는 다음과 같은 '캐싱(Caching)' 전략을 도입하기로 결정했다.
- 사용자가 특정 게시물의 'AI 요약 보기'를 요청한다.
- 서버는 가장 먼저, 데이터베이스에 해당 게시물의 요약이 이미 저장되어 있는지 확인한다.
- 만약 요약이 있다면 (Cache Hit): AI 모델을 호출하지 않고, 데이터베이스에 저장된 요약을 즉시 사용자에게 보여준다. (비용 발생 없음)
- 만약 요약이 없다면 (Cache Miss):
- 그때서야 최초로 한 번 AI 모델을 호출하여 요약을 생성한다.
- 생성된 요약을 데이터베이스에 저장하여, 다음 요청을 위한 '캐시'로 만든다.
- 사용자에게 생성된 요약을 보여준다.
이 아키텍처를 적용함으로써, AI 요약 기능의 총비용은 더 이상 '사용자 수'나 '요청 횟수'에 비례하지 않게 되었다. 대신, 내 블로그의 '총 게시물 수' 에 비례하게 되었다. 게시물이 1,000개라면, 최악의 경우에도 AI 모델은 최대 1,000번만 호출된다.
이것으로 나는 '비용'이라는 첫 번째 관문을 통과할 수 있는, 기술적으로나 경제적으로나 지속 가능한 설계도를 완성했다. 2부에서는, 이 설계도를 실제 코드로 구현하는 과정을 기록해 보려 한다.
