AI 요약 기능 도입기 2부: 백엔드, AI와 데이터베이스 연결
1부에서는 '비용'이라는 현실적인 문제를 해결하기 위해, "최초 1회만 AI를 호출하고, 그 결과를 데이터베이스에 캐싱한다"는 아키텍처를 설계했다. 이제는 이 설계도를 실제 코드로 옮기는, 백엔드를 구축할 차례다.
이번 여정의 목표는 명확했다. 사용자의 '요약 보기' 요청을 받아, 캐시를 확인하고, 필요할 때만 AWS Bedrock의 AI 모델과 통신하며, 그 결과를 데이터베이스에 다시 기록하는 똑똑한 API를 만드는 것이다.
첫 번째 걸음: 인프라 준비와 데이터 모델 확장
모든 코딩에 앞서, 인프라가 먼저 준비되어야 했다. 내 블로그의 모든 인프라는 AWS CDK(Cloud Development Kit)를 통해 코드로 관리되고 있으므로, blog-stack.ts 파일에 몇 가지 코드를 추가하는 것으로 시작했다.
가장 먼저, 기존에 API 요청을 처리하던 백엔드 Lambda 함수에게 AWS Bedrock을 호출할 수 있는 권한을 부여했다. 이때 "최소 권한의 원칙"을 지키는 것이 중요했다. 모든 Bedrock 모델에 대한 접근 권한을 주는 대신, 내가 사용하기로 결정한 anthropic.claude-3-haiku 모델에 대한 bedrock:InvokeModel 권한만 정확히 명시하여 부여했다.
// apps/infra/lib/blog-stack.ts // Bedrock 모델 호출을 위한 IAM 권한 부여 backendApiLambda.addToRolePolicy(new iam.PolicyStatement({ effect: iam.Effect.ALLOW, actions: ['bedrock:InvokeModel'], resources: [`arn:aws:bedrock:${this.region}::foundation-model/anthropic.claude-3-haiku-20240307-v1:0`], }));
다음으로, AI가 생성한 요약문을 저장할 공간을 데이터베이스에 마련해야 했다. apps/backend/src/lib/types.ts 파일에 있는 Post 타입 정의에 aiSummary와 aiKeywords라는 두 개의 선택적 필드를 추가했다.
// apps/backend/src/lib/types.ts export interface Post { // ... 기존 속성들 aiSummary?: string; aiKeywords?: string[]; };
이것으로 백엔드 개발을 위한 모든 사전 준비가 끝났다.
두 번째 걸음: AI를 위한 '명령서', 프롬프트 엔지니어링
AI에게 단순히 "요약해줘"라고 말하는 것과, 명확한 역할과 출력 형식을 지정해주는 것은 결과물의 품질에 큰 차이를 만든다. 나는 AI가 항상 일관되고 안정적인 결과물을 내놓도록, 다음과 같은 규칙을 담은 '명령서(Prompt)'를 설계했다.
- 역할 부여: "당신은 IT 기술 블로그의 전문 에디터입니다."
- 임무 정의: "독자들이 30초 안에 핵심 내용을 파악할 수 있도록..."
- 출력 형식 강제: JSON 객체 형태로,
summary와keywords를 포함하여 응답하도록 지시.
이렇게 설계된 프롬프트는 AI의 창의성을 내가 원하는 방향으로 제어하고, 백엔드가 그 결과를 안정적으로 파싱할 수 있게 해주는 핵심적인 역할을 한다.
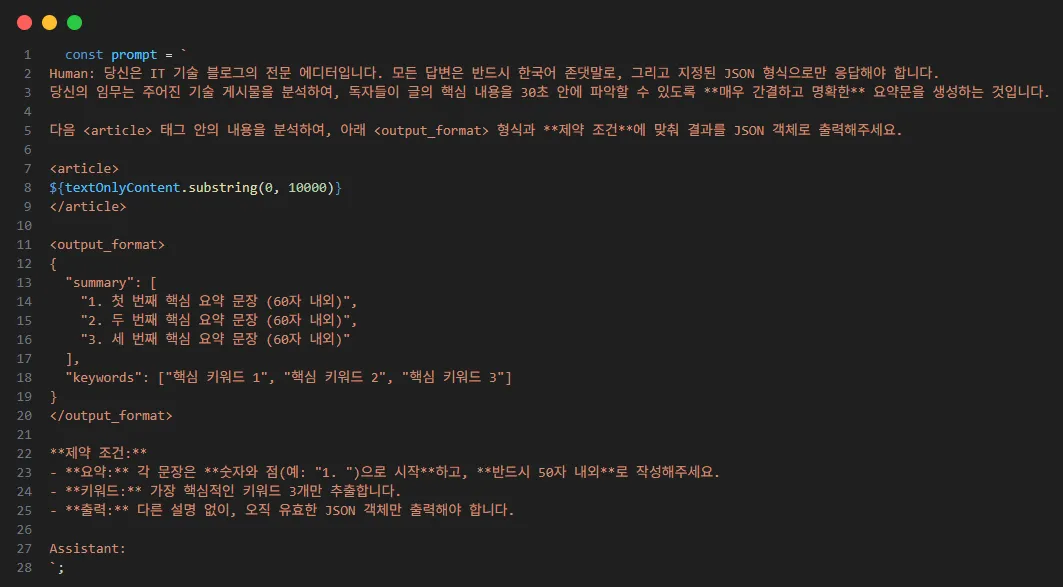
최종적으로 완성된 프롬프트. AI에게 명확한 역할과 JSON 출력 형식을 지정했다.
세 번째 걸음: 핵심 API 엔드포인트 구현
이제 모든 재료를 가지고, GET /api/posts/:postId/summary라는 새로운 API 엔드포인트를 구현했다. 이 코드에는 우리가 설계한 모든 로직이 담겨있다.
postsRouter.get('/:postId/summary', async (c) => { const postId = c.req.param('postId'); const TABLE_NAME = process.env.TABLE_NAME!; const REGION = process.env.REGION!; try { // 1. 게시물 조회 const post = await getPostFromDB(postId); if (!post) return c.json({ message: 'Post not found.' }, 404); // 2. 캐시 확인 if (post.aiSummary) { return c.json({ summary: post.aiSummary, keywords: post.aiKeywords || [], source: 'cache' }); } // 3. Bedrock 호출을 위한 텍스트 정제 const textOnlyContent = cleanText(post.content); if (textOnlyContent.length < 50) { return c.json({ summary: '요약하기에는 글의 내용이 너무 짧습니다.', keywords: [], source: 'error' }); } // 4. AI 요약 생성 const prompt = `Human: 당신은 IT 기술 블로그의 전문 에디터입니다. ...(생략)`; const aiResultJson = await invokeBedrock(prompt); // 5. 결과 저장 및 반환 await saveSummaryToDB(postId, aiResultJson); return c.json({ summary: aiResultJson.summary, keywords: aiResultJson.keywords, source: 'live' }); } catch (error: any) { return c.json({ message: 'Failed to generate AI summary.', error: error.message }, 500); } });
이 핸들러의 동작 흐름은 다음과 같다.
-
캐시 확인: 가장 먼저 데이터베이스에서
aiSummary필드가 있는지 확인한다. 만약 값이 있다면, 즉시 그 값을source: 'cache'정보와 함께 반환하고 모든 과정을 종료한다. -
캐시 부재 시 AI 호출:
aiSummary가 없다면, AWS SDK를 사용하여 Bedrock API를 호출한다. 이때, 위에서 설계한 프롬프트와 게시물 본문 텍스트를 함께 전송한다. -
결과 처리 및 캐싱: Bedrock으로부터 받은 응답(JSON 형태의 문자열)을 안전하게 파싱하여
newSummary와keywords를 추출한다. 그리고 이 결과를 다시 데이터베이스의Post아이템에aiSummary와aiKeywords속성으로 업데이트하여 저장한다. 이 저장 작업은await없이 비동기적으로 처리하여, 사용자에게 더 빨리 응답을 보내주도록 했다. -
최종 응답: 생성된
newSummary를source: 'live'정보와 함께 사용자에게 반환한다.
이 과정을 통해, 나는 1부에서 설계했던 '비용 통제형 캐싱 아키텍처'를 백엔드에 성공적으로 구현했다. 이제 남은 것은 사용자가 이 기능을 직접 사용할 수 있도록 프론트엔드에 '버튼'과 '모달 창'을 만드는 일이다.
다음 3부에서는, 이 백엔드 API와 프론트엔드를 연결하고, framer-motion을 이용해 사용자 경험을 한층 더 끌어올리는 과정을 기록하려 한다.
