[UI/UX 개선 1부]
메인 페이지 개선: 확장성을 고려한 페이지네이션 API 설계와 구현
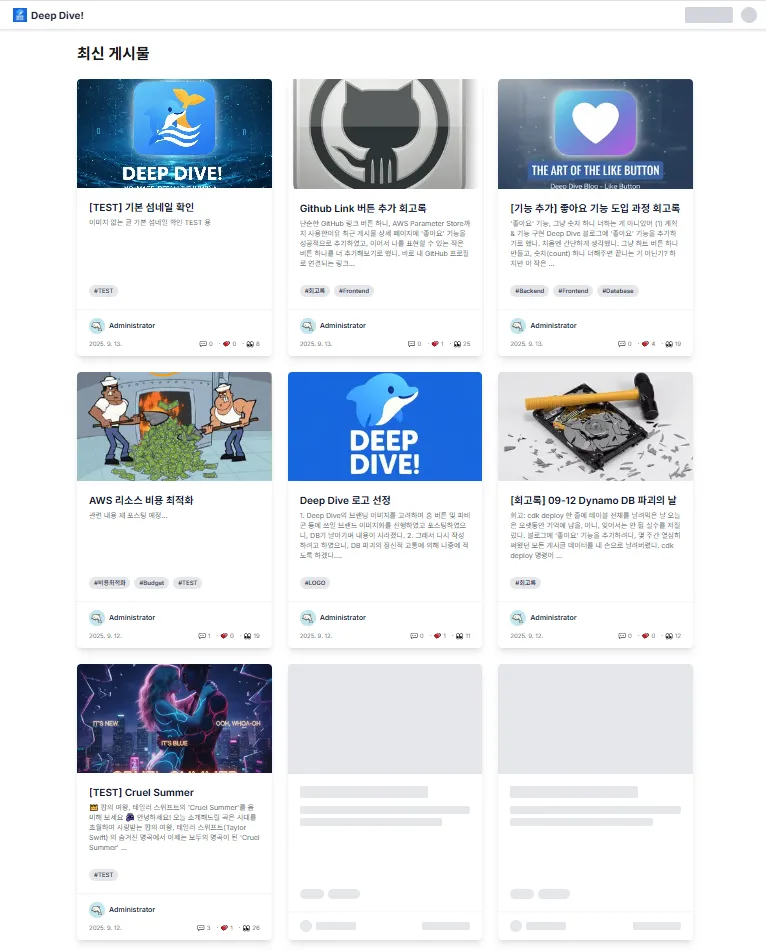
설명: 스켈레톤 UI 완성된 메인 페이지의 모습. 사용자는 초기 게시물들을 즉시 볼 수 있으며, 스크롤을 내리면 다음 콘텐츠가 로드될 것을 암시하는 '로딩스피너'가 위치해 있다.
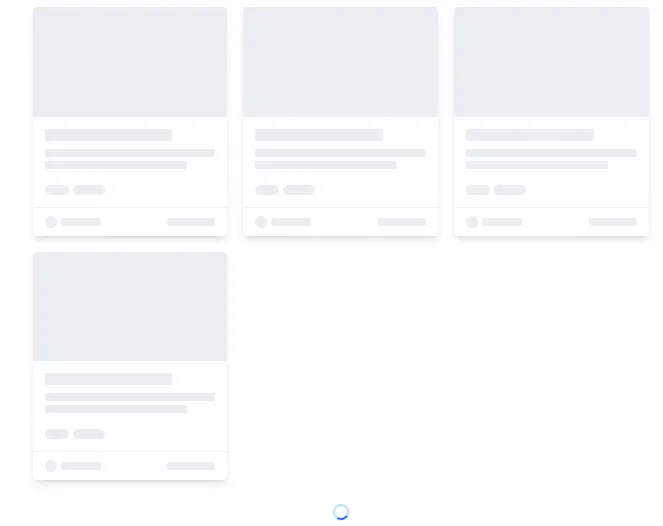
지금까지 Deep Dive! 블로그의 메인 페이지는 단순했습니다. 서버에서 모든 게시물을 한 번에 불러와, 깔끔한 그리드(Grid) 형태로 보여주는 방식이었습니다. 기능적으로는 부족함이 없었지만, 블로그에 글이 쌓여갈수록 두 가지 질문이 머릿속을 떠나지 않았습니다.
- "게시물이 100개, 1000개가 되어도 지금처럼 빠를 수 있을까?"
- "사용자가 이 많은 글 속에서 원하는 정보를 즐겁게 탐색하게 하려면 무엇이 더 필요할까?"
이 질문에 답하기 위해, 저는 메인 페이지를 단순한 '게시물 목록'에서 사용자가 콘텐츠를 즐겁게 '탐색하는 경험'으로 바꾸기 위한 고도화 프로젝트를 시작했습니다. 이 글은 그 첫 번째 단계로, 백엔드의 확장성 문제를 해결하고 미래를 위한 견고한 기반을 다지는 페이지네이션 API의 설계 및 구현 과정을 상세히 기록한 것입니다.
1. 문제 정의: 확장성의 한계
현재 아키텍처의 가장 큰 문제는 백엔드의 확장성이었습니다. GET /posts API는 DB에 있는 모든 게시물을 한 번에 조회하여 반환합니다. 게시물이 수백 개만 되어도 Lambda의 메모리 사용량과 응답 시간은 선형적으로 증가할 것이고, 이는 곧 성능 저하와 비용 증가로 이어질 것이 자명했습니다.
이 문제를 해결하기 위한 핵심은 '페이지네이션(Pagination)', 즉 데이터를 잘게 나누어 필요한 만큼만 요청하고 응답하는 것이었습니다.
2. 페이지네이션 전략: 왜 Cursor 기반인가?
페이지네이션에는 전통적인 '오프셋(Offset)' 방식(page=2&limit=10)과 '커서(Cursor)' 방식이 있습니다. 저는 커서 기반 페이지네이션을 선택했습니다.
- 오프셋 방식의 문제: 데이터가 실시간으로 추가/삭제되는 환경에서,
2페이지를 요청했을 때 이전에 봤던 데이터가 중복으로 보이거나 일부 데이터를 건너뛰는 문제가 발생할 수 있습니다. 또한, 데이터가 많아질수록 뒤 페이지로 갈수록(OFFSET값이 커질수록) 데이터베이스가 스캔해야 할 행이 많아져 성능이 저하됩니다. - 커서 방식의 장점: "마지막으로 봤던 항목 다음부터 10개를 줘"라는 방식으로 요청합니다. 이는 상태를 저장하지 않으므로(stateless) 데이터 변경에 영향을 받지 않으며, 항상 특정 지점부터 조회하므로 성능이 일정하게 유지됩니다. DynamoDB의
LastEvaluatedKey는 이 커서 기반 페이지네이션을 구현하기 위한 완벽한 도구입니다.
3. API 설계: 안전하고 명확한 계약
위 전략에 따라, GET /api/posts API의 규격을 새롭게 설계했습니다.
-
요청 (Request):
limit(optional, number): 한 번에 가져올 게시물 수. 기본값은 12.cursor(optional, string): 다음 페이지를 요청하기 위한 '책갈피'.
-
응답 (Response):
interface PaginatedPosts { posts: Post[]; nextCursor: string | null; // 다음 페이지가 있으면 cursor 문자열, 없으면 null }
보안 강화: 커서(Cursor) 암호화
DynamoDB의 LastEvaluatedKey는 테이블의 파티션 키, 정렬 키 등 내부 구조를 담고 있는 JSON 객체입니다. 이를 클라이언트에 그대로 노출하는 것은 불필요한 정보 유출의 위험이 있습니다.
이 문제를 해결하기 위해, 간단하지만 효과적인 암호화 계층을 추가했습니다.
- 인코딩 (백엔드):
LastEvaluatedKey객체를JSON.stringify()로 문자열로 만든 뒤,Buffer.from(...).toString('base64')를 사용하여 외부에 의미를 알 수 없는 Base64 문자열로 변환하여nextCursor로 전달합니다. - 디코딩 (백엔드): 클라이언트로부터
cursor값을 받으면, Base64 디코딩과JSON.parse()를 통해 다시 DynamoDB가 이해할 수 있는ExclusiveStartKey객체로 복원합니다.
이 과정은 API 응답 시간에 거의 영향을 주지 않으면서, API의 보안 수준을 크게 향상시킵니다.
4. 백엔드 구현: Hono와 DynamoDB QueryCommand
실제 구현은 Hono 라우터와 AWS SDK v3의 QueryCommand를 사용하여 진행했습니다.
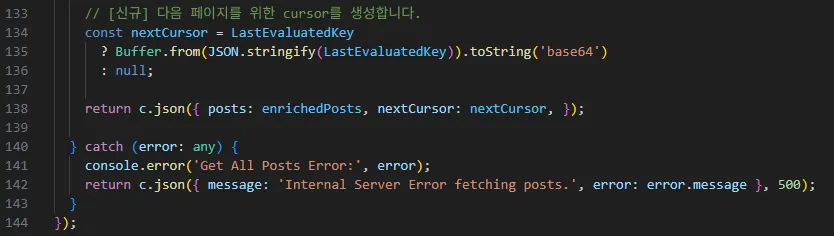
설명:
GET /posts핸들러의 핵심 로직.zod를 사용해 쿼리 파라미터를 안전하게 파싱하고,cursor유무에 따라ExclusiveStartKey를 설정하는 부분을 보여준다.
// 파일 위치: apps/backend/src/routes/posts.router.ts postsRouter.get('/', tryCookieAuthMiddleware, async (c) => { // 1. 쿼리 파라미터를 Zod로 안전하게 파싱하고 기본값을 설정합니다. const { limit, cursor } = z.object({ limit: z.coerce.number().int().positive().default(12), cursor: z.string().optional(), }).parse(c.req.query()); try { const commandParams: QueryCommandInput = { // ... (TableName, IndexName 등) Limit: limit, }; // 2. cursor가 있으면 디코딩하여 ExclusiveStartKey로 사용합니다. if (cursor) { const decodedKey = JSON.parse(Buffer.from(cursor, 'base64').toString('utf-8')); commandParams.ExclusiveStartKey = decodedKey; } // ... (권한에 따른 필터링 로직) // 3. DynamoDB에 쿼리를 실행하고, Items와 LastEvaluatedKey를 받습니다. const { Items, LastEvaluatedKey } = await ddbDocClient.send(new QueryCommand(commandParams)); // ... (게시물 데이터 후처리 로직) // 4. LastEvaluatedKey가 있으면 인코딩하여 nextCursor를 생성합니다. const nextCursor = LastEvaluatedKey ? Buffer.from(JSON.stringify(LastEvaluatedKey)).toString('base64') : null; return c.json({ posts: enrichedPosts, nextCursor: nextCursor, }); } catch (error: any) { /* ... */ } });
디버깅 회고: Zod와 undefined의 함정
구현 과정에서 흥미로운 문제를 마주했습니다. 프론트엔드에서 limit 파라미터 없이 API를 호출하자, 백엔드에서 ZodError: expected number, received NaN 오류가 발생했습니다.
원인은 프론트엔드 API 클라이언트가 ?limit=undefined와 같은 쿼리 문자열을 생성했고, 백엔드의 z.coerce.number()가 문자열 'undefined'를 NaN으로 변환했기 때문이었습니다.
이 문제는 두 단계에 걸쳐 해결했습니다.
- 프론트엔드(
api.ts):limit이나cursor값이null또는undefined일 경우, 애초에 쿼리 파라미터에 포함시키지 않도록 수정했습니다. - 백엔드(
posts.router.ts):zod스키마의.optional()을.default(12)로 변경하여,limit파라미터가 아예 없는 경우에도 안전하게 기본값을 사용하도록 방어 코드를 강화했습니다.
5. 프론트엔드 전략: SSR의 장점과 CSR의 장점을 모두 취하는 방법
Next.js App Router 환경에서 가장 큰 고민은 "어디까지 서버에서 처리하고, 어디부터 클라이언트에게 맡길 것인가?"였습니다.
- 서버 컴포넌트의 장점: 첫 페이지 데이터를 서버에서 미리 렌더링하여 보내주므로, 사용자는 접속 즉시 콘텐츠를 볼 수 있습니다. 이는 초기 로딩 성능(LCP)에 매우 중요합니다.
- 클라이언트 컴포넌트의 장점: '더 보기' 버튼 클릭과 같이 사용자의 상호작용에 따라 데이터를 동적으로 불러오고 상태를 관리하는 데 필수적입니다.
저는 이 두 가지의 장점을 모두 취하기 위해, 메인 페이지를 두 개의 컴포넌트로 역할을 분리하는 하이브리드 렌더링 전략을 선택했습니다.
page.tsx(서버 컴포넌트): '지휘자' 역할을 합니다. 페이지 진입 시, 오직 첫 페이지 데이터만 백엔드 API를 통해 미리 조회합니다.PostList.tsx(클라이언트 컴포넌트): '오케스트라' 역할을 합니다. 지휘자로부터 받은 첫 페이지 데이터를 즉시 화면에 그리고, 그 이후의 모든 동적인 작업('더 보기' 클릭, 추가 데이터 로딩, 로딩 상태 관리)을 전담합니다.
이 구조를 통해, 사용자는 서버 렌더링의 빠른 초기 속도를 경험하면서도, 클라이언트 렌더링의 부드러운 동적 상호작용을 함께 누릴 수 있게 됩니다.
6. 로직 캡슐화: useInfinitePosts 커스텀 훅
페이지네이션 로직(현재 페이지 추적, 데이터 배열 합치기, 마지막 페이지 여부 판단 등)은 복잡하며, 여러 곳에서 재사용될 수 있습니다. 저는 이 복잡성을 UI 컴포넌트로부터 분리하기 위해, useLike 훅과 유사한 패턴으로 useInfinitePosts라는 커스텀 훅을 만들었습니다.
이 훅의 핵심은 SWR(Stale-While-Revalidate) 라이브러리의 useSWRInfinite입니다.
설명:
useSWRInfinite의 핵심인getKey함수. 이전 페이지의nextCursor를 기반으로 다음 페이지를 요청할 URL을 동적으로 생성하는 로직을 보여준다.
// 파일 위치: apps/frontend/src/hooks/useInfinitePosts.ts // getKey 함수는 SWR에게 다음 페이지를 요청할 URL(키)을 알려줍니다. const getKey = (pageIndex: number, previousPageData: PaginatedPosts | null) => { // 마지막 페이지에 도달했다면, null을 반환하여 요청을 중단합니다. if (previousPageData && !previousPageData.nextCursor) return null; // 첫 페이지의 URL if (pageIndex === 0) return `/posts?limit=${POSTS_PER_PAGE}`; // 다음 페이지의 URL (이전 페이지의 커서 사용) return `/posts?limit=${POSTS_PER_PAGE}&cursor=${previousPageData!.nextCursor}`; }; // ... useSWRInfinite 훅 호출 ... // 최종적으로 컴포넌트에서 사용할 상태와 함수들을 깔끔하게 정리하여 반환합니다. return { posts, // 모든 페이지의 게시물을 합친 배열 error, isRefreshing, // 추가 페이지 로딩 또는 갱신 상태 isReachingEnd, // 마지막 페이지 도달 여부 loadMore: () => setSize(size + 1), // '더 보기' 함수 };
이 훅 덕분에, PostList 컴포넌트는 복잡한 내부 로직을 알 필요 없이, 그저 posts를 화면에 그리고 '더 보기' 버튼에 loadMore 함수를 연결하기만 하면 됩니다.
7. 로딩 경험의 완성: 스켈레톤 UI와 무한 스크롤
이제 모든 조각을 맞출 시간입니다.
Step 1: 스켈레톤 UI 제작
먼저, PostCard의 레이아웃과 정확히 일치하는 PostCardSkeleton 컴포넌트를 만들었습니다. Tailwind CSS의 animate-pulse 클래스를 사용하여 은은하게 반짝이는 효과를 주어, 사용자가 로딩 중임을 직관적으로 인지할 수 있도록 했습니다.
Step 2: '더 보기'에서 '자동 로드'로 진화
초기 계획은 '더 보기' 버튼을 클릭하는 방식이었지만, 더 나은 사용자 경험을 위해 무한 스크롤을 구현하기로 결정했습니다. 이를 위해 Intersection Observer API를 활용했습니다.
Intersection Observer는 특정 요소가 화면에 나타나는지를 효율적으로 감지할 수 있는 브라우저 API입니다. 저는 이 API를 useIntersectionObserver라는 커스텀 훅으로 만들고, '더 보기' 버튼 역할을 할 페이지 하단의 빈 div를 관찰 대상으로 지정했습니다.
// 파일 위치: apps/frontend/src/components/PostList.tsx // 1. Intersection Observer 훅을 호출합니다. // rootMargin: '200px' 옵션으로, 관찰 대상이 화면에 보이기 200px 전에 미리 감지합니다. const { setTarget, entry } = useIntersectionObserver({ rootMargin: '200px' }); // 2. 관찰 결과에 따라 다음 페이지를 로드합니다. useEffect(() => { // 관찰 대상이 보이고, 로딩 중이 아니며, 마지막 페이지가 아닐 때 if (entry?.isIntersecting && !isRefreshing && !isReachingEnd) { loadMore(); } }, [entry, isRefreshing, isReachingEnd, loadMore]); return ( <> <div className="grid ..."> {posts.map(post => <PostCard ... />)} {isRefreshing && <PostCardSkeleton ... />} </div> {/* 3. 이 보이지 않는 div가 스크롤의 끝을 감지하는 '트리거' 역할을 합니다. */} <div ref={setTarget} className="h-10"> {isRefreshing && <Spinner />} </div> </> );
이 로직을 통해, 사용자가 페이지 하단으로 스크롤하면 '트리거' div가 뷰포트에 들어오고, useEffect가 이를 감지하여 다음 페이지 로드를 자동으로 시작합니다. rootMargin 옵션 덕분에 사용자가 스크롤을 멈추고 기다리기 전에 로딩이 시작되어, 매우 부드럽고 끊김 없는 경험을 제공할 수 있게 되었습니다.
최종 결과 및 회고
이 일련의 고도화 작업을 통해, Deep Dive! 블로그의 메인 페이지는 이제 다음과 같은 특징을 갖추게 되었습니다.
- 확장성: 게시물이 수천 개가 되어도 안정적인 성능을 보장하는 페이지네이션 API.
- 빠른 초기 로딩: 서버 사이드 렌더링을 통해 사용자가 즉시 첫 페이지 콘텐츠를 확인.
- 쾌적한 탐색 경험: 스켈레톤 UI와 무한 스크롤을 통해 부드럽고 끊김 없는 동적 로딩.
단순한 기능 구현을 넘어, 시스템의 확장성과 사용자 경험의 디테일까지 고려하는 과정은 쉽지 않았지만, 그만큼 시스템 전체의 완성도를 한 단계 끌어올리는 값진 경험이었습니다. "어떻게 하면 더 나은 경험을 제공할 수 있을까?"라는 질문을 멈추지 않는 것이, 결국 더 견고하고 사랑받는 서비스를 만드는 길임을 다시 한번 깨닫게 되었습니다.
