#2. 백엔드 리팩토링 : 거대해진 라우터 분리하기
서론: 계획을 현실로
이전 포스팅 #1.백엔드 리팩토링 계획단계에서는 posts.router.ts 파일 하나에 과도하게 집중된 책임을 분산시키기 위해 라우터(Router) - 서비스(Service) - 리포지토리(Repository) 의 3계층 아키텍처를 계획했다.

계획을 실행단계로 진행한 과정, 즉 실제 코드를 어떻게 점진적으로 개선해 나갔는 지에 대해서 어떤 기술적 판단과 예상치 못한 디버깅 상황을 마주했는지, 그리고 최종적으로 코드가 어떻게 변화 했는지 기록하고자 한다.
1단계: 데이터 조회(GET) 로직 분리
백엔드 리팩토링을 진행하며 가장 유의한 것은 '안전성'이다. 이미 잘 동작하는 시스템을 섣불리 변경하다가는 더 큰 문제를 야기할 수 있다고 생각했다. 따라서 데이터의 상태를 변경하지 않는 읽기(Read) 로직부터 분리를 시작했다. 그중에서도 가장 복잡하고 개선의 효과가 클 것으로 예상되는 GET / (전체 게시물 조회) 엔드포인트가 첫 번째 수술 대상이 되었다.
Before & After: 100줄 핸들러의 극적인 변화
리팩토링의 결과를 가장 직관적으로 보여주는 것은 코드의 변화다. 기존 GET / 핸들러는 페이지네이션, 사용자 권한 분기, 데이터 보강을 위한 추가 DB 조회 등 무려 100줄에 가까운 코드가 작성되어 있었다. 이랬던 코드가 리팩토링 후에는 단 30줄 내외의 명확하고 간결한 코드로 다시 태어났다.
[리팩토링 전: 주석 포함 100line]
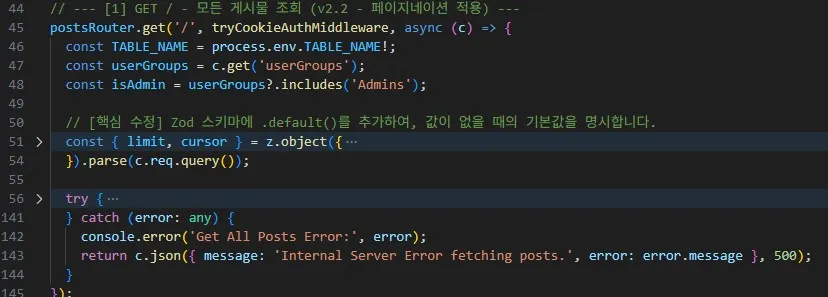
[리팩토링 후 : 주석 포함 30line]
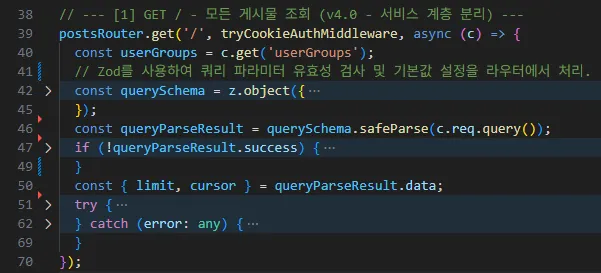
변경 전: 모든 것을 하려 했던 핸들러 이전의 코드는 HTTP 요청을 받아 유효성을 검증하고, DynamoDB 쿼리를 직접 생성하며, isAdmin 플래그에 따라 쿼리 조건을 바꾸고, 조회된 각 게시물마다 댓글 수를 다시 조회하기 위해 루프를 돌며 DB에 반복적으로 접근했다. 이 모든 일이 하나의 핸들러 함수 안에서 이루어졌다.
변경 후: 자신의 역할에만 집중하는 핸들러
// apps/backend/src/routes/posts.router.ts (After) postsRouter.get('/', tryCookieAuthMiddleware, async (c) => { // 1. HTTP 요청에서 필요한 정보 추출 및 유효성 검증 const userGroups = c.get('userGroups'); const { limit, cursor } = validateGetPostsQuery(c.req.query()); try { // 2. 비즈니스 로직은 서비스 계층에 완전히 위임 const result = await postsService.getPostList({ limit, cursor, userGroups }); // 3. 서비스의 결과를 HTTP 응답으로 반환 return c.json(result); } catch (error: any) { // ... 에러 처리 ... } });
이제 라우터는 DynamoDB의 존재 자체를 알지 못한다. 복잡한 데이터 보강 로직이나 페이지네이션의 내부 구현에 대해 전혀 신경 쓰지 않는다. 오직 postsService.getPostList라는 잘 정의된 창구를 통해 "게시물 목록 좀 줘"라고 요청하고, 받은 결과를 클라이언트에게 전달하는 명확한 책임만 수행한다.
구조적 개선: N+1 쿼리 문제의 해결
이러한 극적인 단순화는 단순히 코드를 다른 파일로 옮기는 것만으로 이루어지지 않는다. 책임을 분리하는 과정에서 기존 코드의 비효율적인 구조를 발견하고 개선할 기회를 얻게 된다. 이번 리팩토링의 가장 큰 기술적 성과 중 하나는 고질적인 성능 문제였던 N+1 쿼리를 구조적으로 해결한 것이다.
기존에는 게시물 목록을 가져온 뒤(1번 쿼리), 각 게시물의 댓글 수를 알기 위해 N개의 게시물만큼 N번의 추가 쿼리를 실행했다. 리팩토링 후에는 이 책임이 Service와 Repository로 나뉘면서 다음과 같이 최적화되었다.
-
Repository (데이터 전문가):
posts.repository.ts에는findAllPosts(게시물 목록 조회)와findCommentCounts(여러 게시물의 댓글 수를 한 번에 조회)라는 명확한 역할의 함수를 두었다.findCommentCounts는Promise.all을 이용해 여러 요청을 병렬로 처리하여 효율을 극대화한다. -
Service (비즈니스 지휘자):
posts.service.ts의getPostList함수는 이 두 리포지토리 함수를 조율하는 지휘자 역할을 한다. 먼저findAllPosts를 호출해 게시물 목록을 가져온 뒤, 여기서 얻은 게시물 ID들을 모아findCommentCounts를 단 한 번만 호출한다.
// apps/backend/src/services/posts.service.ts (핵심 로직) async function getPostList(options) { // 1. 기본 게시물 목록 조회 (DB 접근 #1) const { posts, nextCursor } = await postsRepository.findAllPosts(options); // 2. 댓글 수 일괄 조회 (DB 접근 #2) const postIds = posts.map(p => p.postId); const commentCounts = await postsRepository.findCommentCounts(postIds); // 3. 두 데이터를 조합하여 최종 결과 생성 const enrichedPosts = posts.map(post => ({ /* ... */ })); return { posts: enrichedPosts, nextCursor }; }
결과적으로, (1+N)번 발생하던 DB 조회가 단 2번의 효율적인 호출로 최적화되었다. 이는 단순히 코드가 깔끔해지는 것을 넘어, 애플리케이션의 성능과 비용 효율성을 직접적으로 개선하는 실질적인 성과다.
예상치 못한 난관: 테스트 코드와의 사투
리팩토링은 항상 순탄하지만은 않다. GET /:postId (단일 게시물 조회) 로직을 분리했을 때, 기존에 잘 통과하던 테스트가 실패하기 시작했다. 에러 메시지는 expected 500 to be 200. 서버가 내부 오류로 크래시하고 있다는 의미였다.
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯ Failed Tests 1 ⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯ FAIL __tests__/routes/posts.router.test.ts > Posts API (/api/posts) > PUT /:postId > should update a post successfully if user is an admin and the author TypeError: Cannot read properties of undefined (reading 'title') ❯ __tests__/routes/posts.router.test.ts:121:33 119| const response = await request(server).put('/api/posts/1').set('Cookie', 'idToken=fake-admin-token').send({ ti… 120| expect(response.status).toBe(200); 121| expect(response.body.post.title).toBe('Updated Title'); | ^ 122| }); 123| }); ⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯[1/1]⎯
원인은 애플리케이션 코드가 아닌 테스트 코드에 있었다. 리팩토링으로 인해 내부 DB 호출 횟수와 순서가 findPostById -> incrementViewCount -> checkUserLikeStatus -> findAllPostTitlesForNav의 4단계로 변경되었지만, 테스트 코드는 여전히 기존 방식대로 2번의 DB 호출만 가정하고 Mock(가짜 데이터)을 설정하고 있었던 것이다. 준비된 Mock 응답이 없자 테스트 환경의 DB 클라이언트가 에러를 일으켰고, 이것이 서버 크래시로 이어졌다.
이 경험은 리팩토링이 단순히 기능 코드만을 대상으로 하는 작업이 아님을 명확히 보여주었다. 코드의 내부 구조를 바꾸는 것은 그 코드의 동작을 보증하는 테스트 코드와 함께 가는 여정이며, 잘 작성된 테스트는 리팩토링 과정에서 발생할 수 있는 미묘한 논리적 오류를 잡아주는 가장 든든한 안전망 역할을 한다는 것을 다시 한번 확인할 수 있었다.
문제를 해결하기 위해, 실제 코드의 DB 호출 순서와 횟수에 맞춰 테스트 코드의 Mock 설정을 4단계로 정확하게 수정했고, 비로소 모든 테스트가 다시 녹색 불을 밝혔다. 이 디버깅 과정은 시간은 걸렸지만, 리팩토링된 코드의 동작 방식에 대한 이해도를 한층 더 높여주는 계기가 되었다.
데이터 무결성과의 싸움: 쓰기 로직 분리
읽기 로직 분리를 통해 아키텍처 개선의 효과와 안정성을 확인한 후, 다음 단계는 데이터의 상태를 직접 변경하는 쓰기(Write) 로직으로 나아갔다. 데이터의 생성, 수정, 삭제를 다루는 POST, PUT, DELETE 핸들러는 데이터의 정합성과 무결성을 해치지 않도록 더욱 신중한 접근이 필요했다.
가장 복잡했던 퍼즐: 게시물 수정(PUT) 로직 분해하기
게시물 수정(PUT /:postId) 핸들러는 이번 리팩토링에서 가장 복잡한 퍼즐이었다. 수정 요청이 들어왔을 때, 단순히 요청된 데이터만 DB에 반영하는 것이 아니라 여러 비즈니스 규칙에 따른 추가 작업이 필요했기 때문이다.
content가 변경되면, 검색 및 미리보기를 위한summary를 다시 생성해야 했다.content안의 이미지 URL이 바뀌면, 게시물 썸네일(thumbnailUrl)도 함께 갱신해야 했다.tags배열이 변경되면, 기존 태그와 새 태그를 비교하여 어떤 태그를 DB에서 삭제하고, 어떤 태그를 새로 추가할지 계산(diff)해야 했다.
이 모든 책임이 뒤섞여 있던 기존 핸들러는 이제 각자의 전문 분야를 가진 Service와 Repository로 명확하게 분리되었다.
1. Service (비즈니스 전략가): '무엇을' 할지 계산
posts.service.ts의 updatePost 함수는 이제 비즈니스 전략가 역할을 맡는다. DB에 어떻게 저장할지는 고민하지 않고, '무엇을' 변경해야 하는지만을 계산하는 데 집중한다.
// apps/backend/src/services/posts.service.ts (핵심 로직) async function updatePost(postId, userId, updateInput) { // 1. 수정 권한 확인 const existingPost = await postsRepository.findPostById(postId); if (existingPost.authorId !== userId) return 'forbidden'; // 2. 파생 데이터 재계산 const finalUpdateData: Partial<Post> = { ...updateInput }; if (updateInput.content) { finalUpdateData.summary = recalculateSummary(updateInput.content); finalUpdateData.thumbnailUrl = extractThumbnail(updateInput.content); } // 3. 태그 변경 사항 계산 (Diff) if (updateInput.tags) { const { toDelete, toAddOrUpdate } = calculateTagChanges(existingPost, updateInput.tags); // 4. 계산된 결과를 Repository에 전달하여 실행 요청 await postsRepository.syncTagsForPost(postId, toDelete, toAddOrUpdate); } // 5. 최종 게시물 데이터 업데이트 요청 return await postsRepository.updatePost(postId, finalUpdateData); }
2. Repository (데이터 실행 전문가): '어떻게' 할지 실행
posts.repository.ts는 서비스로부터 명확한 지시를 받아, 이를 실제 DB 작업으로 변환하는 실행 전문가 역할을 한다. UpdateExpression을 동적으로 만들거나 BatchWriteCommand를 구성하는 복잡한 DB 관련 코드는 모두 이곳에 캡슐화되었다.
이러한 분리를 통해, "태그 동기화 로직에 버그가 있다면 posts.service.ts를, DB 업데이트 성능이 문제라면 posts.repository.ts를 보면 된다"는 명확한 디버깅 가이드라인이 생겼다.
외부 시스템 연동의 정석: 책임의 경계를 긋다
게시물 삭제(DELETE /:postId) 로직은 또 다른 종류의 책임 분리를 보여주는 좋은 예시다. 게시물 삭제는 단순히 DB의 데이터를 지우는 것뿐만 아니라, S3에 업로드된 관련 이미지 파일들도 함께 삭제해야 하는 외부 시스템 연동 작업을 포함한다.
리팩토링 후, 이 두 가지 책임은 명확한 경계를 갖게 되었다.
- Service: S3 SDK를 사용하여 이미지 URL을 파싱하고 삭제 요청을 보내는 외부 시스템과의 통신을 책임진다. 이는 비즈니스 로직의 일부로 간주된다.
- Repository: 게시물과 태그 아이템의
isDeleted플래그를true로 바꾸고 TTL을 설정하는, 순수한 데이터 영속성 관리에만 집중한다.
이제 S3 관련 정책이 변경되더라도 repository 코드는 전혀 영향을 받지 않으며, 반대로 DB 스키마가 변경되어도 S3 관련 로직은 수정할 필요가 없다.
최종 결과: 가벼워진 라우터와 명확해진 책임
모든 핵심 로직의 이전이 끝난 후, 마지막으로 posts.router.ts에 남아있던 좋아요, AI 요약 등 주변 기능들도 각각의 전문 서비스(likes.service.ts, ai.service.ts)로 완전히 분리했다.
그 결과, 1000줄에 육박했던 posts.router.ts 파일은 이제 주석 제외 250줄 내외의 간결한 코드로 변모했다. 더 이상 ddbDocClient나 S3Client, BedrockRuntimeClient 등 저수준의 클라이언트를 import하지 않는다. 오직 Hono와 미들웨어, 그리고 잘 정의된 서비스 계층의 창구 함수들만 알고 있을 뿐이다.
정량적 성과:
- 코드 라인 수:
posts.router.ts(1000줄 -> 250줄),posts.service.ts(신규 350줄),posts.repository.ts(신규 300줄) - 파일 분리: 1개의 거대 파일 -> 역할에 따라 3개의 전문 파일 + a (
ai.service.ts)
정성적 성과:
- 예측 가능성: 새로운 기능을 추가하거나 기존 로직을 수정할 때, 어떤 파일을 수정해야 할지 명확하게 예측할 수 있게 되었다.
- 변경의 용이성: "DB 스키마 변경은
repository에서, 비즈니스 규칙 변경은service에서" 라는 원칙 하에, 변경의 영향 범위를 최소화할 수 있게 되었다. - 테스트 용이성: 비즈니스 로직을 DB나 HTTP 요청과 분리하여 순수한 함수처럼 단위 테스트할 수 있는 견고한 기반이 마련되었다.
결론
이번 리팩토링 여정은 단순히 낡은 코드를 정리하는 작업이 아니었다. 프로젝트의 성장에 따라 코드 구조가 어떻게 함께 진화해야 하는지를 깊이 있게 경험하는 과정이었다. 코드는 한번 작성하고 끝나는 정적인 존재가 아니라, 비즈니스의 성장에 발맞춰 끊임없이 개선해야 함을 다시 한번 깨달았다.
