AWS Lambda Cold Start: Next.js SSR 블로그 진입 성능 개선
서론
Deep Dive! 블로그의 프론트엔드는 Next.js와 서버리스 기반으로 Lambda에 Docker이미지 형식으로 저장되어 실행된다. 프론트엔드는 Next.js App Router(SSR)를 AWS Lambda와 Docker로, 백엔드는 Hono 프레임워크 기반의 별도 Lambda API로 구성했다. 대부분의 핵심 기능 구현을 마치고 안정화 단계에 접어들었을 때, 문득 블로그의 첫 로딩 속도가 만족스럽지 않다는 점을 인지하게 되었다. 특히 장시간 사용하지 않다가 접속할 때, 페이지가 표시되기까지 몇 초간의 지연이 발생하는 현상이 있었다.
문제의 원인으로 Docker 이미지 기반으로 배포된 프론트엔드 Lambda의 "콜드 스타트(Cold Start)" 를 가장 먼저 의심했다. 이 포스팅은 이 가설을 단순한 직감이 아닌, 데이터를 통해 증명하고, 다양한 해결 방안을 탐색하며, 최종적으로 주어진 제약 조건 하에서 최적의 해결책을 찾아 나가는 전 과정을 기록한 것이다. 1부에서는 문제 정의부터 원인 분석, 그리고 해결 전략을 수립하는 과정을 다룬다.
1. 렌더링 경로 분석: 요청부터 응답까지
문제의 원인을 정확히 파악하기 위해, 사용자가 브라우저에서 블로그 주소로 접속했을 때 발생하는 전체 요청 흐름을 먼저 분석했다.
- Client -> DNS (Route 53) -> CloudFront: 사용자의 요청은 Route 53을 통해 IP 주소를 찾고, AWS의 CDN 서비스인 CloudFront 엣지 로케이션에 도달한다.
- CloudFront -> FrontendServerLambda (SSR): CloudFront에 캐시된 응답이 없을 경우, 요청은 Next.js SSR을 담당하는 프론트엔드 Lambda로 전달된다. 이 과정에서 첫 번째 잠재적 병목인 프론트엔드 콜드 스타트가 발생할 수 있다.
- FrontendServerLambda -> API Gateway -> BackendApiLambda: 프론트엔드 서버는 페이지를 렌더링하는 데 필요한 데이터(추천 글, 최신 글 목록 등)를 얻기 위해, 내부 네트워크를 통해 API Gateway로 HTTP 요청을 보낸다. 이 요청은 다시 백엔드 API를 담당하는 Lambda로 전달된다. 이 과정에서 두 번째 잠재적 병목인 백엔드 콜드 스타트가 발생할 수 있다.
- BackendApiLambda -> DynamoDB: 백엔드 Lambda는 DynamoDB에 쿼리를 보내 필요한 데이터를 조회한다.
- 응답: 조회된 데이터는 역순(DynamoDB -> Backend -> Frontend -> CloudFront -> Client)으로 사용자에게 전달되어 최종 페이지가 렌더링된다.
이 분석을 통해, 전체 지연 시간은 각 단계의 소요 시간, 특히 두 Lambda 함수의 콜드 스타트 시간에 크게 좌우될 것임을 예측할 수 있었다.
2. 성능 측정 시스템 구축: AWS X-Ray 도입
가설을 데이터로 증명하기 위해, 분산 추적 시스템인 AWS X-Ray를 도입하기로 결정했다. 초기 목표는 프론트엔드부터 백엔드까지의 전체 요청 흐름을 하나의 서비스 맵으로 시각화하는 것이었다.
인프라 설정 및 백엔드 연동
CDK(blog-stack.ts)를 통해 FrontendServerLambda, BackendApiLambda의 tracing을 ACTIVE로 설정하고, aws-xray-sdk를 백엔드(index.ts, dynamodb.ts)에 통합하는 작업은 비교적 순조롭게 진행되었다. 이를 통해 백엔드 API를 직접 호출했을 때의 트레이스는 정상적으로 수집되는 것을 확인했다.
프론트엔드 연동 시도와 실패
문제는 프론트엔드와 백엔드의 트레이스를 연결하는 과정에서 발생했다.
-
시도 1: 공용 모듈(
api.ts)에서의import: 서버/클라이언트 양쪽에서 모두 사용되는api.ts파일에aws-xray-sdk를import하자, Next.js 빌드 과정에서 클라이언트 번들에 서버 전용 모듈(fs,dgram등)이 포함되려다Module not found빌드 에러가 발생했다. -
시도 2: 서버 전용 모듈 및 Instrumentation Hook:
.server.ts파일 분리,'use server'지시어, Next.js의 공식instrumentation.ts등 다양한 방법을 시도했지만, 모두 유사한 빌드 에러로 이어지거나, 빌드는 성공하더라도 런타임에서 효과가 없었다. 후자의 경우,aws-xray-sdk의captureHTTPsGlobal이 Node.js 18+의undici기반 글로벌fetch를 추적하지 못하는 것이 원인으로 분석되었다.
전략 수정: "분리 분석" 채택
프론트엔드 X-Ray 연동을 위한 아키텍처 변경(API 클라이언트 완전 분리 등)은 "방어적 기능 추가" 원칙에 위배되는 큰 리팩토링이라고 판단했다. 따라서, 완벽한 서비스 맵을 구축하는 것을 잠정 중단하고, 각 서비스의 성능을 개별적으로 측정하여 조합하는 "분리 분석" 전략으로 선회했다.
- 프론트엔드 성능: CloudWatch Logs의
REPORT라인에서Init Duration을 직접 확인. - 백엔드 성능: AWS X-Ray 트레이스를 통해
Init Duration및 DynamoDB 하위 세그먼트 확인.
3. 데이터 기반 원인 분석: 병목 구간 식별
"분리 분석" 전략에 따라, 의도적으로 콜드 스타트를 유발한 후 각 데이터 소스에서 성능 지표를 수집했다.
팩트 1: 프론트엔드 콜드 스타트 시간
CloudWatch Logs Insights에서 아래 쿼리를 사용하여 FrontendServerLambda의 성능을 분석했다.
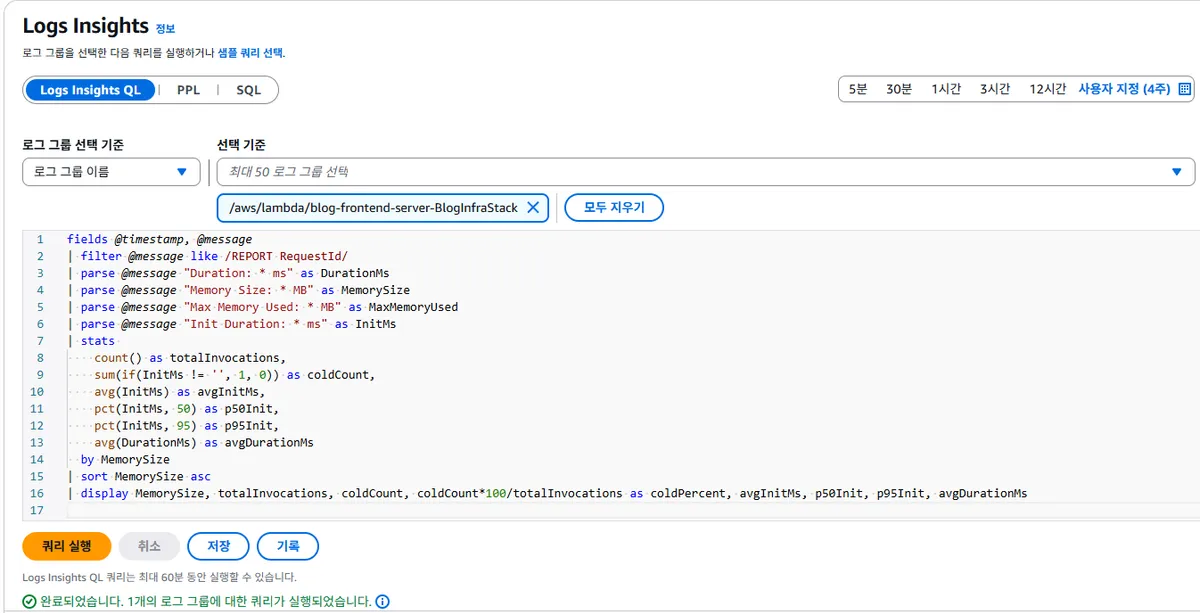
fields @timestamp, @message | filter @message like /REPORT RequestId/ | parse @message "Duration: * ms" as DurationMs | parse @message "Memory Size: * MB" as MemorySize | parse @message "Max Memory Used: * MB" as MaxMemoryUsed | parse @message "Init Duration: * ms" as InitMs | stats count() as totalInvocations, sum(if(InitMs != '', 1, 0)) as coldCount, avg(InitMs) as avgInitMs, pct(InitMs, 50) as p50Init, pct(InitMs, 95) as p95Init, avg(DurationMs) as avgDurationMs by MemorySize | sort MemorySize asc | display MemorySize, totalInvocations, coldCount, coldCount*100/totalInvocations as coldPercent, avgInitMs, p50Init, p95Init, avgDurationMs
분석 결과, FrontendServerLambda의 평균 콜드 스타트 시간(avgInitMs)은 약 3.8초 ~ 4.4초에 달하는 것으로 확인되었다. REPORT 로그 샘플은 다음과 같다.
REPORT RequestId: fe95... Duration: 682.96 ms ... Init Duration: 4401.24 ms ...
팩트 2: 백엔드 성능
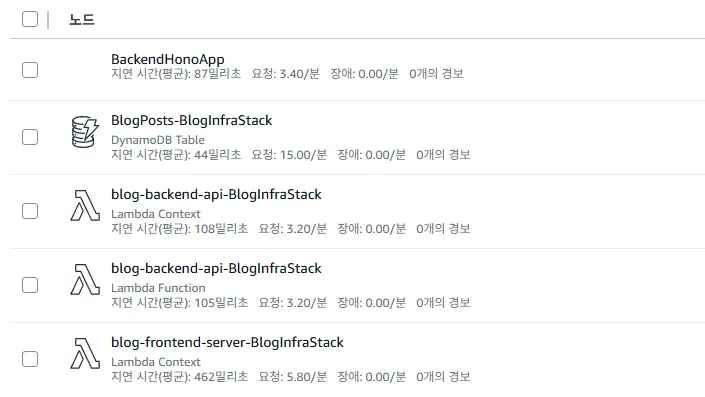
X-Ray 트레이스를 분석한 결과, BackendApiLambda의 성능은 다음과 같았다.
- 콜드 스타트 시간 (
Initialization): 약 0.4초 이하 - DB 처리 시간 (
DynamoDB Query): 약 0.1초 이하
결론
수집된 데이터를 종합한 결과, "첫 로딩 지연"의 주된 원인이 FrontendServerLambda의 긴 콜드 스타트 시간임이 명확하게 규정되었다. 이제 과제는 "어떻게 프론트엔드 Lambda의 콜드 스타트를 줄일 것인가?"로 좁혀졌다.
Part 2: 해결 전략 탐색과 최종 결정
문제의 원인이 프론트엔드 Lambda의 콜드 스타트임이 데이터로 증명되었다. 이제 이 문제를 해결하기 위한 다양한 방안을 테이블 위에 올려놓고, "프리티어 준수"와 "최소한의 아키텍처 변경"이라는 제약 조건 하에서 최적의 해결책을 탐색하는 과정을 거쳤다.
4. 기각된 해결책들: 왜 그 길을 가지 않았는가?
문제 해결을 위해 여러 가지 근본적인 아키텍처 변경안을 검토했다.
- ECS/EKS 또는 EC2 기반 상시 대기 서버: Lambda를 포기하고 상시 실행되는 컨테이너나 가상 머신을 사용하는 방법이다. 콜드 스타트를 완벽히 제거할 수 있지만, 24/7 실행되는 컴퓨팅 자원에 대한 비용이 발생하여 "프리티어 준수" 원칙에 정면으로 위배되므로 기각했다.
- AWS App Runner: 완전 관리형 컨테이너 서비스로, ECS/EKS보다 관리가 용이하다. 하지만 이 역시 프로비저닝된 인스턴스 기반의 비용 모델을 가져 프리티어 초과 가능성이 높고, CDK로 세밀하게 제어하는 현재 아키텍처의 유연성을 해칠 수 있어 채택하지 않았다.
- 프로비저닝된 동시성 (Provisioned Concurrency): Lambda 실행 환경을 항상 "웜" 상태로 유지시켜 콜드 스타트를 제거하는 가장 확실한 Lambda 내장 기능이다. 하지만 비용 계산 결과, 가장 낮은 메모리(512MB)로 설정하더라도 프리티어 제공량을 세 배 이상 초과하는 상당한 고정 비용이 발생하여 기각했다.
- SSG/ISR로의 아키텍처 전환: 최고의 성능과 비용 효율성을 제공하는 근본적인 해결책이다. 하지만 현재 블로그는 댓글, 좋아요, 로그인 상태 등 동적인 요소가 많고, 이를 모두 서버에서 한번에 렌더링하여 완전한 페이지를 제공하는 SSR 방식의 개발 편의성과 유연성이 큰 장점이라고 판단했다. SSG/ISR로 전환 시 발생하는 대규모 프론트엔드 리팩토링과 동적 데이터 처리의 복잡성 증가라는 비용을 고려하여, 이 방안은 향후 트래픽이 크게 증가했을 때를 대비한 장기 과제로 보류하기로 결정했다.
5. 실마리 발견: 데이터 속에 숨겨진 힌트
근본적인 아키텍처 변경 대신, 현재 SSR 구조 내에서 최적화할 수 있는 방법을 찾기로 했다. "메모리 증가는 콜드 스타트에 효과가 없을 것"이라는 초기 가설을 검증하기 위해, FrontendServerLambda의 메모리를 1024MB에서 2048MB로 상향하여 테스트를 진행했다.
CloudWatch Logs Insights 쿼리를 통해 두 설정 간의 Init Duration을 비교 분석한 결과, 놀라운 사실을 발견했다.
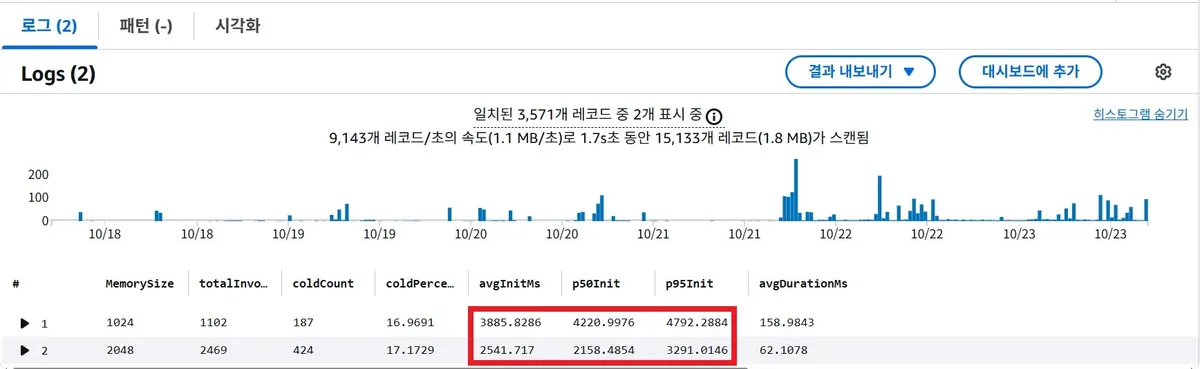
| 메모리 크기 (MB) | 평균 콜드 스타트 시간 (ms) | p95 콜드 스타트 시간 (ms) |
|---|---|---|
| 1024 | 3845.94 (약 3.8초) | 4821.11 (약 4.8초) |
| 2048 | 2422.62 (약 2.4초) | 3280.74 (약 3.3초) |
메모리를 두 배로 늘렸을 뿐인데, 평균 콜드 스타트 시간이 약 1.4초 단축되는 유의미한 개선 효과가 데이터로 증명되었다. 이는 콜드 스타트의 Init Duration에 포함된 "애플리케이션 초기화" 단계가 CPU 성능에 영향을 받으며, Lambda 메모리 증가에 따른 vCPU 성능 향상이 이 시간을 단축시킨 결과로 분석된다.
6. 최종 전략: "가성비"와 "확률"의 조화
이 데이터 분석 결과를 바탕으로, "프리티어 준수"와 "SSR 아키텍처 유지"라는 제약 조건 하에서 최적의 성능 개선 전략을 다음과 같이 수립했다.
-
Lambda 메모리 상향 (1024MB -> 2048MB)
- 역할: 콜드 스타트가 발생하더라도, 그 지연 시간 자체를 데이터로 검증된 2.4초 수준으로 단축시킨다.
- 근거: 현재 트래픽 수준에서 컴퓨팅 비용을 계산한 결과, 실행 시간(
Duration) 또한 절반 가까이 줄어들어, 메모리 증가에 따른 GB-초 사용량 증가는 프리티어 범위 내에서 충분히 감당 가능한 수준으로 판단했다.
-
저비용 워밍 (Keep-Warm) 전략 도입
- 역할: 콜드 스타트의 발생 빈도 자체를 최소화한다.
- 근거: EventBridge Scheduler를 사용하여 10분 간격으로 Lambda를 호출하는 방식은, Lambda와 EventBridge의 프리티어 제공량(월 100만 건 이상)에 훨씬 못 미치는 월 약 4,320회의 호출만 발생시키므로 사실상 무료로 운영 가능하다. 이 간단한 조치로, 대부분의 사용자는 2.4초의 지연조차 겪지 않고 "웜" 상태의 빠른 응답을 경험하게 된다.
이 두 가지를 조합하는 것이, 현재 아키텍처를 유지하면서 최소한의 비용으로 사용자 경험을 체감 가능한 수준으로 개선하는 최적의 균형점이라고 결론 내렸다.
-2부 예고-
1부에서는 데이터 기반으로 문제를 진단하고, 다양한 해결책을 탐색하여 최종 전략을 수립하는 과정을 다루었다. 이어지는 2부에서는 이 전략을 실제로 구현하는 코드 레벨에서의 과정, 즉 CDK를 이용한 Lambda 메모리 설정 및 EventBridge Scheduler 구현 방법과, 최적화 적용 후의 최종 성능 검증 결과를 상세히 다룰 예정이다.
