지난 포스팅에서는 PostgreSQL을 연동하여 데이터의 영속성을 확보하고, Ingress와 Managed Certificate를 통해 도메인 연결 및 HTTPS 보안을 적용했다. 이로써 서비스는 기능적으로나 보안적으로 실제 운영이 가능한 형태를 갖추게 되었다.
하지만 운영 환경에서는 "서비스가 잘 돌아가고 있다"는 막연한 믿음만으로는 부족하다. 트래픽이 급증할 때 CPU 사용량은 얼마나 되는지, 메모리 누수는 없는지, 파드(Pod)가 비정상적으로 재시작되지는 않는지 등 시스템의 상태를 정량적인 데이터로 파악할 수 있어야 한다.
이번 포스팅에서는 쿠버네티스 환경의 표준 모니터링 스택인 Prometheus와 Grafana를 GKE 클러스터에 구축하고, 인위적인 부하 테스트를 통해 실제 메트릭 변화를 관측한 과정을 기록한다.
1. 모니터링 아키텍처 및 도구 선정
쿠버네티스 생태계에서 모니터링을 구축할 때 가장 널리 사용되는 조합은 Prometheus와 Grafana이다.
- Prometheus: 시계열 데이터베이스를 기반으로 메트릭을 수집하고 저장하는 역할을 한다. 쿠버네티스 API와 연동하여 동적으로 생성되는 파드들을 자동으로 감지할 수 있다.
- Grafana: Prometheus가 수집한 데이터를 쿼리하여 시각적인 대시보드로 보여주는 역할을 한다.
- Helm: 이 복잡한 모니터링 스택(Prometheus, Grafana, Alertmanager, Node Exporter 등)을 개별적으로 설치하는 것은 비효율적이므로, 쿠버네티스 패키지 매니저인 Helm을 사용하여
kube-prometheus-stack차트를 통해 일괄 배포하는 방식을 택했다.
2. Helm을 이용한 모니터링 스택 배포
로컬 환경에 Helm을 설치한 후, GKE 클러스터에 모니터링 전용 네임스페이스를 생성하고 스택을 배포했다.
# Prometheus 커뮤니티 차트 저장소 추가 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update # monitoring 네임스페이스에 스택 설치 helm install monitoring prometheus-community/kube-prometheus-stack -n monitoring --create-namespace
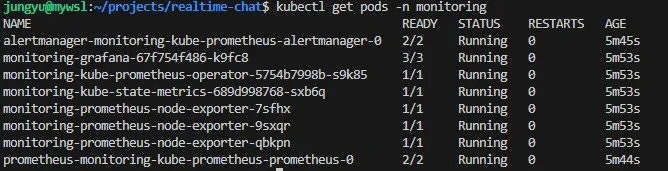
설치 후 kubectl get pods -n monitoring 명령어를 통해 수집기(Prometheus), 시각화 도구(Grafana), 그리고 노드 상태를 체크하는 에이전트(Node Exporter)들이 정상적으로 실행 중임을 확인했다.

3. Grafana 대시보드 접속 및 설정
보안상 모니터링 대시보드는 외부 인터넷(LoadBalancer/Ingress)에 노출하지 않고, 필요할 때만 로컬에서 접근할 수 있도록 포트 포워딩(Port Forwarding) 방식을 사용했다.
# 로컬 3000 포트를 Grafana 서비스로 포워딩 kubectl port-forward svc/monitoring-grafana 3000:80 -n monitoring
Grafana의 초기 admin 비밀번호는 쿠버네티스 Secret에 저장되어 있으므로, 이를 디코딩하여 확인한 후 로그인했다.
# 비밀번호 확인 kubectl get secret -n monitoring monitoring-grafana -o jsonpath="{.data.admin-password}" | base64 -d; echo
kube-prometheus-stack은 설치 시점에 이미 쿠버네티스 운영에 필요한 핵심 대시보드들을 함께 프로비저닝해준다. 그중 Kubernetes / Compute Resources / Namespace (Pods) 대시보드를 통해 우리 애플리케이션(backend, frontend)이 배포된 default 네임스페이스의 리소스 사용량을 중점적으로 관측하기로 했다.
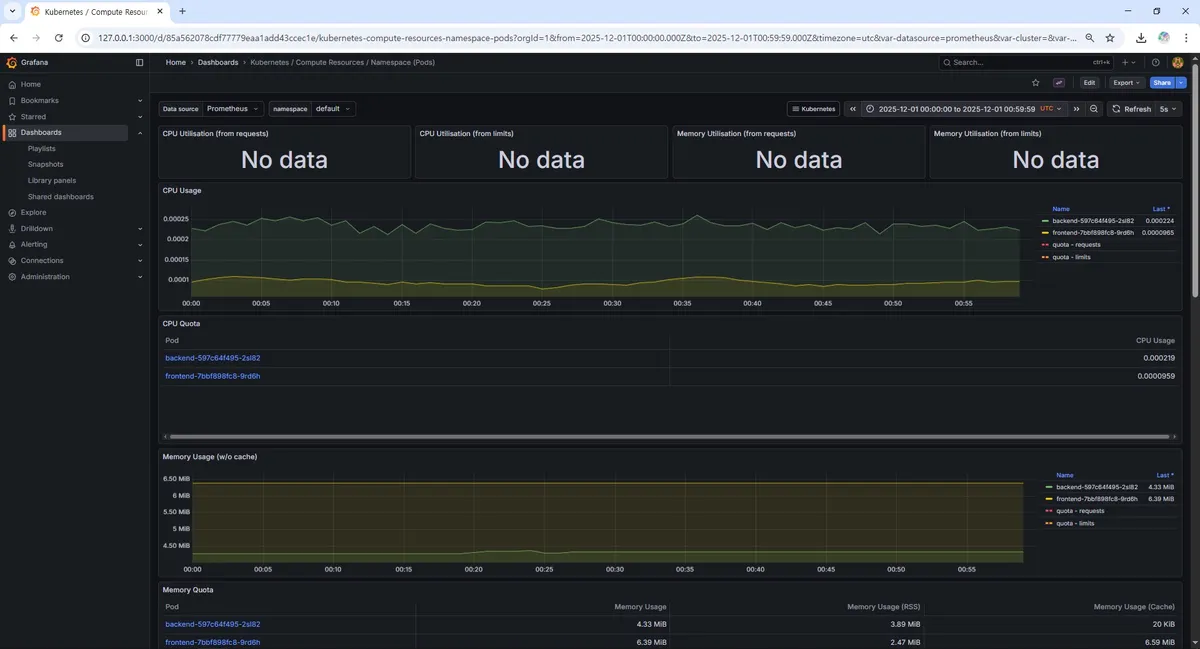
4. 부하 테스트 및 메트릭 관측
구축된 모니터링 시스템이 실제로 유의미한 데이터를 보여주는지 검증하기 위해 인위적인 부하를 발생시켜 보았다. 별도의 복잡한 툴 대신, 쉘 스크립트와 curl을 사용하여 백엔드 서버의 헬스 체크 엔드포인트에 지속적인 요청을 보내는 방식을 사용했다.
# 0.01초 간격으로 요청을 보내는 무한 루프 (터미널 3개 동시 실행) while true; do curl -s https://chat.jungyu.store/ > /dev/null; sleep 0.01; done
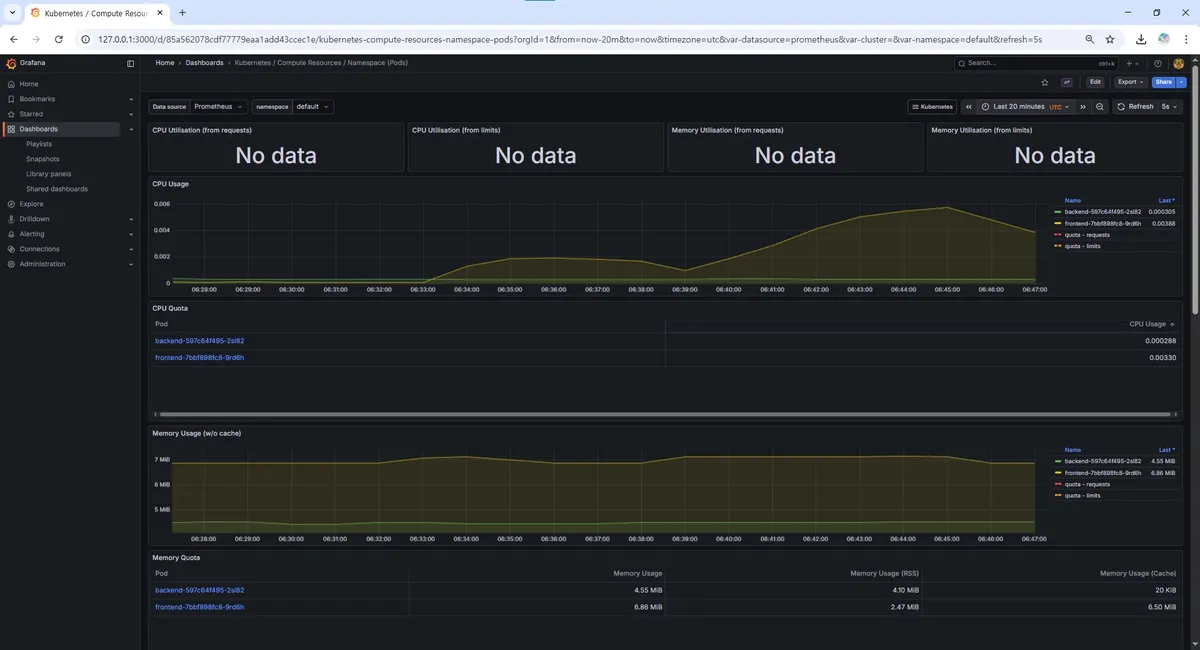
약 5분 (06:39~06:45) 부하를 지속하며 Grafana 대시보드의 변화를 관찰했다.
4.1. CPU 사용량 변화
부하 테스트 시작과 동시에 backend 파드의 CPU 사용량이 급격하게 치솟는 것을 확인할 수 있었다. 평소 유휴 상태에서는 거의 0에 가까웠던 사용량이 요청 처리를 위해 리소스를 점유하며 그래프가 우상향하는 모습이 뚜렷하게 나타났다.
4.2. 네트워크 트래픽 변화
Network I/O 그래프 역시 요청과 응답 패킷량이 동반 상승하는 패턴을 보였다. 이를 통해 서비스가 요청을 정상적으로 수신하고 처리하여 응답하고 있음을 시각적으로 확인할 수 있었다.
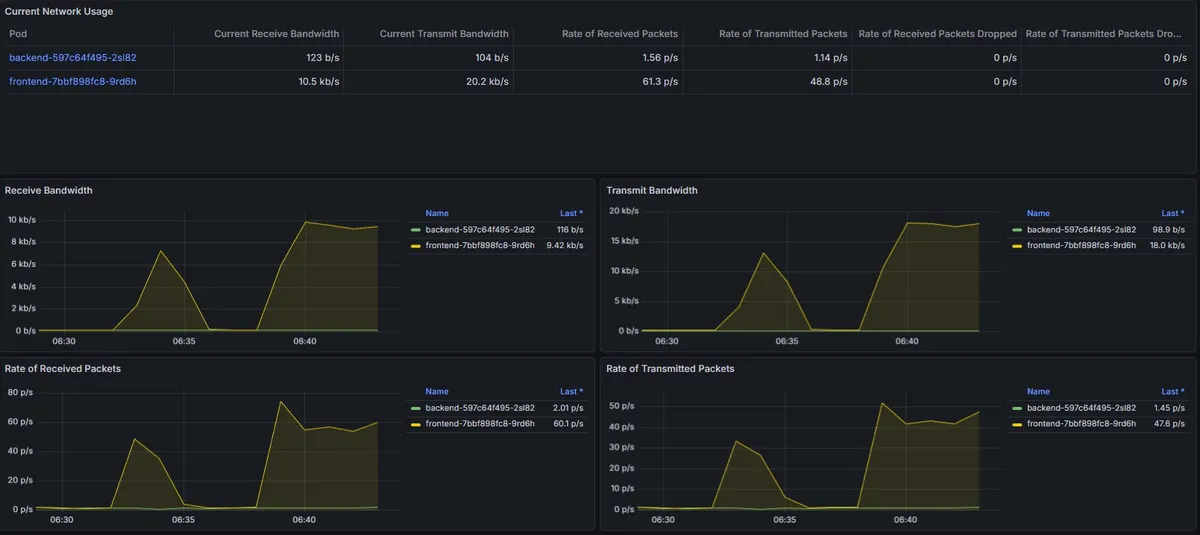
06:39 전 변화는 1개의 터미널에서 테스트 진행하였고 이후 06:39 부터 3개의 터미널에서 진행.
이러한 관측 데이터는 추후 오토스케일링(HPA) 임계치를 설정하거나, 리소스 제한을 최적화하는 데 중요한 근거 자료로 활용될 수 있다.
5. 마무리 및 향후 계획
지금까지 로컬 개발 환경(Docker)에서 시작하여 클라우드 인프라 IaC 구축(Terraform), 배포 자동화(GitOps), 그리고 운영 모니터링(Prometheus/Grafana)까지 이어지는 DevOps의 전체 라이프사이클을 1차적으로 완성했다.
서로 다른 클라우드(AWS 블로그, GCP 채팅)에 존재하는 서비스가 사용자에게는 하나의 경험으로 제공되도록 통합되었으며, 데이터 영속성과 보안까지 갖춘 상태가 되었다.
하지만 프로젝트는 여기서 끝나지 않는다. 현재 구축된 GKE 환경은 쿠버네티스 환경에 대한 운영과 학습 목적에는 최적이지만, 트래픽이 적은 개인 프로젝트를 지속적으로 운영하기에는 비용 효율성 측면에서는 상당히 비합리적이다.
따라서 앞으로는 다음과 같은 고도화 작업을 진행할 예정이다.
- 애플리케이션 고도화: 현재 단일 채팅방 구조를 게시글별 채팅, 관리자 1:1 문의 등으로 확장.
- CI/CD 파이프라인 고도화: 현재
latest태그 고정으로 인해 Argo CD가 이미지 변경을 자동으로 감지하지 못하는 한계를 극복하기 위해, Kustomize 등을 도입하여 이미지 태그를 동적으로 관리하고 완전한 자동 배포 체계 구축. - 비용 최적화 마이그레이션: GKE 환경에서의 학습을 마친 후, Cloud Run이나 단일 VM(Docker Compose) 과 같이 비용이 거의 들지 않는(프리티어 준수) 아키텍처로 마이그레이션하여 지속 가능한 운영 환경 구축.
이러한 고도화 및 아키텍처 최적화 과정을 통해 단순히 '만들어보고 경험하는 것'에 그치지 않고, '효율적으로 실제 운영하는 것'까지 완벽히 해내는 것을 목표로 하고 있다. 앞으로도 기존 Deep Dive!블로그 프로젝트에 MSA 아키텍처로 많은 기능들을 자연스럽게 확장해나가는 과정이 기대된다.
