
#1 이벤트 기반 아키텍처
1. 도입 배경
처음, 기술블로그를 시작하게 된 동기는 학습한 것을 기록하고자 하는 단순한 목적이었다. 그래서 기록하는데에 부족함 없는 읽고, 쓰는 기능이 완벽히 가능한 단순한 CRUD 목적으로 시작했다. 점차 기능을 추가하고 개선해나가면서 Deep Dive! 블로그 프로젝트는 Velog, Tistory와 같은 대형 블로그 플랫폼 수준의 기능을 구현하는 것을 목표로 했다.
다음 단계로, 기존 플랫폼과 차별화되는 고유한 기능을 추가하기로 결정했다.
- 첫 번째로 AWS Bedrock을 이용한 'AI 요약 기능'을 도입했고,
- 두 번째 도전으로 AWS Polly를 활용한 'AI 음성 TTS(Text-to-Speech)' 기능을 구현하기로 했다.
이번 Polly TTS 서비스 기능의 목표는 사용자에게 콘텐츠를 듣는 새로운 경험을 제공하여 기존의 대형 플랫폼의 블로그와 차별화된 기능을 구현하는 것 이다.
2. 초기 아키텍처 설계 (이벤트 기반)
초기 목표는 '완전 자동화'였다. 관리자가 게시물의 발행 상태를 발행 (published)로 변경하면, 후속 음성 생성 과정이 자동으로 처리되는 시스템을 구상했다. 이를 위해 발행상태에 따라 트리거되는 이벤트 기반 아키텍처를 채택했다.
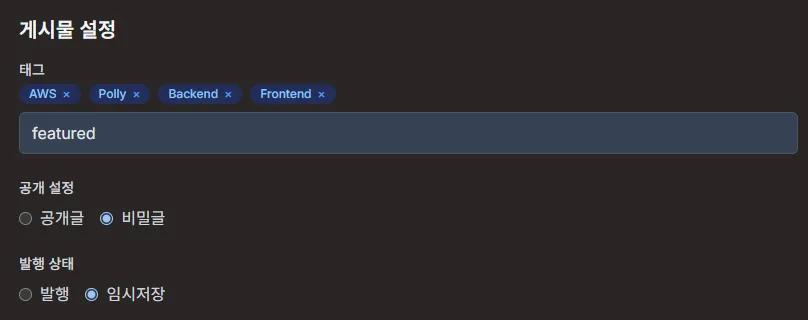
핵심 설계:
- 트리거:
DynamoDB Stream이Post테이블의 아이템 변경을 감지한다. - 실행:
status가published인 이벤트를 필터링하여SpeechSynthesisLambda를 실행, 음성 합성을 시작한다. - 결과 저장 및 알림: 생성된 MP3는
S3에 저장되고, 완료 알림은SNS를 통해UpdateSpeechUrlLambda로 전달된다. - 상태 업데이트:
UpdateSpeechUrlLambda가 최종speechUrl을DynamoDB에 기록한다.
이 설계는 각 서비스가 느슨하게 결합되어 있고, 관리자 개입을 최소화하는 장점이 있었다.
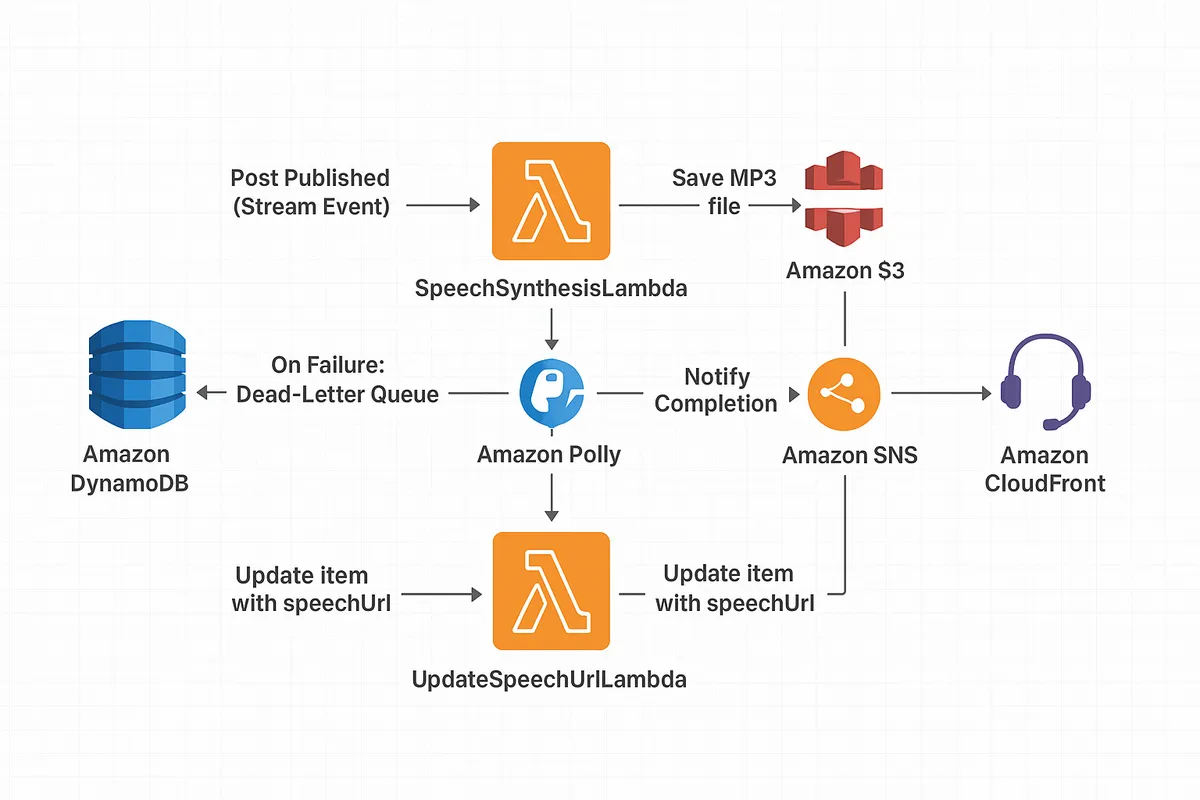
3. 인프라 구축
AWS CDK(TypeScript)를 사용하여 필요한 리소스를 코드로 정의했다. postsTable에 stream을 활성화하고, 두 개의 Lambda 함수와 각각의 트리거, SQS DLQ, 그리고 필요한 IAM Role을 생성했다.
4. 문제 발생: "조용한 실패(Silent Failure)"
인프라 배포 후, 테스트를 위해 새 게시물을 발행했다. 그러나 예상과 달리 시스템은 아무런 반응이 없었다. S3 버킷은 비어 있었고, DynamoDB의 speechUrl 속성은 생성되지 않았다. CloudWatch Logs에도 관련 로그가 전혀 기록되지 않았다.
디버깅 1: Lambda 함수 자체 검증
Lambda 함수 자체의 문제를 확인하기 위해, AWS Lambda 콘솔의 '테스트' 기능으로 SpeechSynthesisLambda를 강제 실행했다.
테스트 결과, INIT 단계에서 TypeError가 발생하는 것을 확인했다. 원인은 CDK 코드에서 Lambda 함수에 IMAGE_BUCKET_NAME 환경 변수를 전달하지 않아 발생한 문제였다. 해당 환경 변수를 추가하고 재배포하여 Lambda 함수 자체는 정상적으로 실행되도록 수정했다.
디버깅 2: 트리거 동작 검증
Lambda 함수는 정상이었지만, 여전히 실제 DynamoDB 이벤트에는 반응하지 않았다. AWS 콘솔에서 DynamoDB 스트림 설정, Lambda 트리거 활성화 상태, IAM 역할의 스트림 읽기 권한을 모두 확인했으나, 구성 상의 문제는 발견되지 않았다.
5. 아키텍처 재검토
이 디버깅 과정을 통해 이벤트 기반 아키텍처의 단점을 확인했다.
- 테스트의 복잡성: 로컬 환경에서 DynamoDB 스트림을 포함한 E2E 테스트를 구성하기 어렵다.
- 문제 추적의 어려움: 이벤트 흐름이 암시적이어서, 문제 발생 시 어느 지점에서 연결이 끊겼는지 파악하기 복잡하다.
이러한 문제들로 인해, 더 제어하기 쉽고 예측 가능한 시스템을 구축하기 위해 아키텍처를 변경하기로 결정했다.
#2 API 기반 아키텍처 전환과 UI/UX 개선
1. 아키텍처 개선 (API 기반)
이벤트 기반 아키텍처의 테스트 및 디버깅 어려움을 해결하기 위해, 관리자가 직접 기능을 제어하는 '명시적 API 기반' 아키텍처로 전환했다.
핵심 설계 변경점:
- 트리거 변경: DynamoDB Stream을 제거하고, 관리자가 호출하는 API 엔드포인트(
POST /api/posts/{postId}/speech)를 새로운 트리거로 사용한다. - 실행 흐름: API 요청을 받은
backendApiLambda가posts.service.ts를 통해 비즈니스 로직(중복 생성 방지 등)을 처리한 후,SpeechSynthesisLambda를 비동기적으로 직접 호출(invoke)한다. - 상태 추적:
Post아이템에speechStatus(PENDING,COMPLETED,FAILED) 속성을 추가하여, 프론트엔드에서 작업 상태를 명확히 인지할 수 있도록 했다.
이 설계는 제어권과 예측 가능성을 높이고, Postman 등을 이용한 테스트를 용이하게 만들었다.
2. 백엔드 및 인프라 리팩토링
변경된 아키텍처에 맞춰 백엔드 코드와 인프라를 수정했다.
- 백엔드:
posts.router.ts에 음성 생성/삭제를 위한 신규 엔드포인트를 추가하고,posts.service.ts에 관련 비즈니스 로직을 구현했다.SpeechSynthesisLambda는 더 이상 스트림 이벤트를 처리하지 않고,backendApiLambda로부터 직접postId와content를 전달받도록 수정했다. - 인프라 (CDK):
SpeechSynthesisLambda의 DynamoDB 스트림 트리거와 관련 IAM 권한을 제거했다. 대신,backendApiLambda가SpeechSynthesisLambda를 호출할 수 있도록lambda:InvokeFunction권한을 부여했다. 기존 검색 기능의OpenSearch 인덱싱을 위한 DynamoDB 스트림 기능은 그대로 유지하여, 기존 기능에 영향을 주지 않도록 방어적으로 수정했다.
3. 두 번째 문제: 403 Access Denied
백엔드 파이프라인은 정상적으로 동작하여 S3에 MP3 파일이 생성되었지만, 브라우저에서 해당 CloudFront URL로 접근 시 403 Forbidden 에러가 발생했다.
브라우저 개발자 도구의 네트워크 탭에서 x-cache: Error from cloudfront 헤더를 통해, CloudFront가 오리진인 S3로부터 에러를 받았음을 확인했다.
권한 문제 디버깅
AWS CLI와 콘솔을 통해 CloudFront와 S3의 설정을 직접 확인하며 여러 가설을 검증했다.
- S3 버킷 정책 검증: 정책에 명시된
AWS:SourceArn의 Distribution ID가 실제 배포된 CloudFront Distribution ID와 일치하는지 확인했다. - S3 객체 존재 여부 검증:
aws s3api head-object명령으로 요청한 키의 객체가 버킷에 실제로 존재하는지 확인했다. - CloudFront 동작(Behavior) 검증:
aws cloudfront get-distribution명령으로cacheBehaviors설정을 확인했다.
분석 결과, CloudFront의 cacheBehaviors 순서가 문제의 원인이었다. /speeches/* 패턴보다 더 일반적인 /*.* 패턴이 배열에서 먼저 위치하여, MP3 파일 요청이 의도치 않은 S3 버킷(웹 에셋용 버킷)으로 잘못 라우팅되고 있었다.
해결: CDK 코드에서 cacheBehaviors 배열의 순서를 조정하여, 가장 구체적인 경로인 /api/*와 /speeches/*가 먼저 평가되도록 수정하여 문제를 해결했다.
4. 오디오 플레이어 UI/UX 개선
기능 구현 후, 사용자 경험을 향상시키기 위해 오디오 플레이어 UI를 고도화했다.
초기 플레이어 (MVP)
처음에는 HTML의 기본 <audio> 태그와 간단한 제어 버튼만을 사용하여 최소 기능의 플레이어를 구현했다. 하지만 모바일 화면에서 레이아웃이 깨지고, 배속 조절과 같은 고급 기능이 없어 사용성이 떨어졌다.

중간 플레이어 (배속 기능 & 커스텀 아이콘 추가)
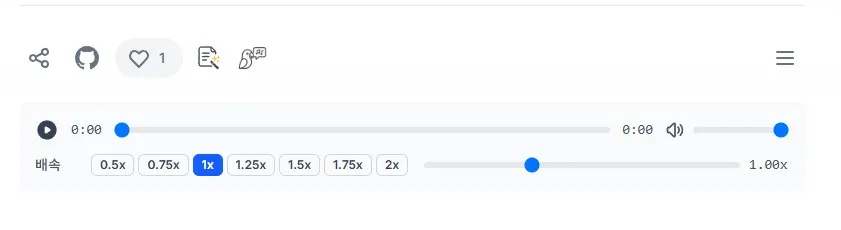
최종 플레이어 (UI/UX 개선 후)
React(useState, useRef, useEffect), Tailwind CSS, Framer Motion을 활용하여 반응형 UI와 풍부한 기능을 갖춘 플레이어를 새로 구현했다.
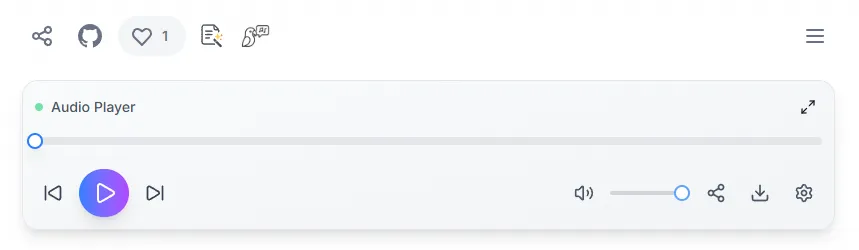
주요 개선 사항:
- 독립 컴포넌트화: 모든 오디오 관련 로직을
AudioPlayer.tsx라는 전문 컴포넌트로 분리하여 재사용성과 유지보수성을 높였다. - 반응형 UI: 화면 크기에 따라 레이아웃과 컨트롤이 동적으로 변경된다.
- PC: 모든 컨트롤(음량, 세분화된 배속 프리셋, 미세 조절 슬라이더)이 항상 표시된다.
- 모바일: "설정(톱니바퀴)" 아이콘을 통해 음량/배속 조절 UI를 토글하여, 컴팩트한 2줄 레이아웃을 유지한다.
- 고급 기능 추가: 10초 앞/뒤로 가기, 버퍼링 상태 시각화, 오디오 다운로드, 최소화/최대화 등 사용자 편의 기능을 추가했다.
- 디자인 개선:
lucide-react아이콘, 그라데이션, 부드러운 애니메이션(framer-motion)을 적용하여 미적 완성도를 높였다.
마치며
Deep Dive 블로그 제작의 초기 목표는 안정적인 CRUD 기능을 기반으로 하는 개인 기록용 블로그였다. 점차 블로그의 기본 기능을 개선하면서, 마크다운 에디터 도입 및 이미지 리사이징, 각종 소셜기능을 추가하고 UI/UX를 개선하면서 목표를 Velog, Tistory와 같은 대형 블로그 플랫폼의 퀄리티를 만들어 내고자 했다.
이후 프로젝트의 방향성은 기존 대형 플랫폼을 목표로 하는 것을 넘어, 차별화된 가치를 제공하는 개인 기술 블로그로 발전시키는 것으로 설정했다.
첫 번째 단계는 AWS Bedrock을 활용한 'AI 요약 기능'의 도입이었다. 이를 통해 콘텐츠 소비의 효율성을 높이는 새로운 가능성을 확인했다.
이번 'Polly TTS 기능' 구현은 그 두 번째 단계였다. 이 기능은 사용자에게 '읽기' 경험 외에 듣기 라는 새로운 선택지를 제공하여 블로그의 접근성을 확장하는 것을 목표로 했다. 이 기능을 구현하는 과정에서, 초기 이벤트 기반 아키텍처가 가진 테스트의 어려움과 디버깅의 복잡성이라는 한계를 확인했다. 이를 해결하기 위해, 더 제어하기 쉽고 예측 가능한 API 기반 시스템으로 아키텍처를 성공적으로 재설계했다.
Deep Dive! 블로그는 단순한 CRUD 기록용 블로그를 넘어, AI 요약과 음성 합성이라는 두 가지 핵심 기능을 통해 특별한 가치를 제공하는 차별화된 블로그로 발전하고 있다고 생각한다.
